一个 Java 程序员跨界:如何用近红外光谱 (NIR) 搞定“智能洗衣”
作为一个写了多年 Java 的程序员,我的日常工作通常聚焦在架构设计与代码实现上。
但在一次出差深入洗衣工厂的业务实地考察中,一个非典型的技术问题摆在了我面前。
这不是关于高并发或微服务,而是关于物理世界的“物质识别”。
一、 业务痛点:当经验主义失效
在实地考察中,我了解到洗衣业务面临的一个核心痛点是“洗损”(洗坏衣服)。
洗衣工厂往往都得有一个至少 10 年经验的老师“镇场”,否则可能都不够赔的。
但仅通过这位老师傅进行把关,一是精力上有漏检,另外流程太后置了:你把衣服交给洗衣门店,然后次日门店告诉你“洗不了”这得多糟心呀。
所以我们就一方面想降低洗损率,另一方面想把流程前置提升客户体验。
这就要求我们要从源头准确判断:面料和污渍。
1、 认错面料的代价
举个真实的案例:一件看着像裘皮的大衣被送来干洗。如果它是真皮,必须干洗,因为如果水洗的话会退鞣严重并容易发霉;但如果它是通过胶水粘合的仿毛(假货),干洗剂会溶解胶水,导致衣服直接脱毛、散架。
2、看不准的污渍
除了面料,污渍识别同样致命。
比如牛奶渍和血渍,如果识别不出,直接上了高温蒸汽或烘干,蛋白质会瞬间固化在纤维里,变成永久性的顽渍。而如果能提前识别,用冷水或双氧水预处理,就能轻松搞定。
为了解决这个问题,我们调研了常规手段,但局限性非常明显:
- 看水洗标:由于供应链鱼龙混杂,标签与实际成分不符的情况非常普遍。
- 感官法:凭借老师傅的手感、眼观、鼻嗅。但随着化纤工艺的进步,高仿面料已能以假乱真,极度依赖人的主观判断容易出错。(后文有验证)
- 燃烧法:虽然准确,但作为有损检测,在实际收衣场景中完全不可行。
问题变得很清晰: 我们需要一种无损、快速且准确的定性分析方案。
起初,我对找到完美方案并不抱太大希望。
但在调研了大量跨行业的技术后,我发现农业(测西瓜甜度)和石化(测油品)领域广泛使用一种叫 近红外光谱 (NIR) 的技术。


虽然这对当时的我来说完全是知识盲区,但直觉告诉我,这种透过光谱看分子指纹的技术,或许就是我们要找的答案。

二、 走出代码舒适区:硬件选型与“笨功夫”
从决定引入 NIR 技术,挑战就从软件层面延伸到了硬件与数据层面。这一阶段的工作量,远超后期的算法开发。
1. 硬件选型的博弈
要将实验室级别的技术落地到洗衣门店,设备必须兼顾便携性和成本。
我调研了市面上几乎所有的微型光谱仪方案:
最终在开发阶段初步锁定了 德州仪器 (TI) 的 DLP 方案,成本还能 cover 住。但毕竟人家是大公司,成熟方案,价格优势不大。
在后续准备落地阶段,考虑到成本因素,在广泛的寻源后,我锁定了一家德国初创公司的产品。
2. 数据冷启动:跑布匹市场与进高校
硬件只是躯壳,数据才是灵魂。为了训练模型,我必须构建一个覆盖面极广的“面料光谱数据库”。
这项工作没有任何捷径,只能靠“笨功夫”:
- 跑市场:“北柯桥,南中大”–这是国内最大的两个面料市场,一个在绍兴柯桥,另一个在广州中大。我们缺少标准的面料数据库,就专门跑到了绍兴柯桥,在各个市场里“流窜”,一家家拜访,收集各种材质和混合比例的布料小样。
- 进高校:另外为了获取更标准的样本数据,我了解到北京服装学院的图书馆有个特别的馆–面料图书馆。我们就钻入图书馆,带着设备对上万块标准面料,逐一扫描、标记、录入。
正是这些脱离了键盘的枯燥采集工作,为后续的模型准确率打下了最坚实的基础。
三、 技术核心:偏最小二乘法 (PLS)
当数据准备就绪,工作重心终于回到了我熟悉的算法领域。

针对光谱数据多重共线性(相邻波长相关性极高)的特点,我们没有直接套用常见的深度学习模型,而是采用了在化学计量学中更经典的 偏最小二乘法 (Partial Least Squares, PLS)。
- 算法逻辑:PLS 能够有效地进行降维,提取出光谱中与面料成分(Y值)相关性最强的潜在变量(Latent Variables),从而克服普通线性回归的过拟合问题。
- 流程:预处理(平滑、求导消除基线漂移) -> PLS 特征提取 -> 建立分类模型。
经过反复调优,我们的定性预测模型在 10 折交叉验证中,准确率达到了 99.24%。其他多分类指标也表现优异:Kappa 0.9576,F1 Macro 0.9613,F1 Micro 0.9618。

四、 盲测实战:算法 VS 资深专家
为了验证模型的实战能力,我们进行了一组严格的对比测试。
我们选取了 5 份未参与训练的高难度面料样本(包含高仿化纤),送检 CMA 认证检测机构进行定量检测(也是一笔不小的钱)。

然后分别进行交给 从业十余年的资深老师傅 和 我们的 NIR 模型 进行定性盲测。
结果具有压倒性的说服力:
| 选手 | 识别结果 | 备注 |
|---|---|---|
| 资深老师傅 | 0 / 5 正确 | 即使允许使用燃烧法,面对高仿面料依然误判 |
| NIR 预测模型 | 5 / 5 正确 | 准确识别出所有成分 |
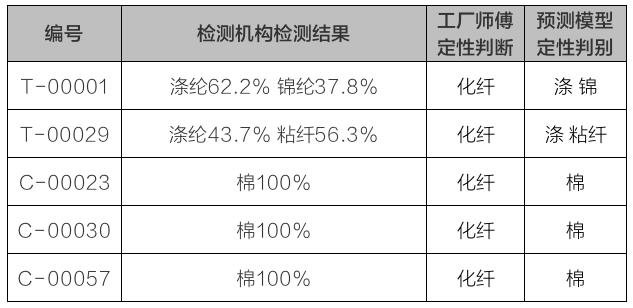
目前,该模型已经覆盖了市场冬季常见面料种类的 98.3%
(冬季衣物价值相比夏季 T 恤价值更高,面料更复杂)。 
我们也对衣物进行了面料识别实战:
随机向一个同事借了一件外套,经过近红外光谱识别后,定性结果为“棉涤混纺,且棉含量偏多”,与其成分标注「棉79.1% 聚酯纤维20.9%」一致。(注:聚酯纤维=涤纶)

五、 进阶挑战:从面料到污渍
搞定了面料,我们并没有停下。就像前文提到的,污渍识别是避免洗衣事故的另一道防线。
既然大部分日常污渍(油、血、奶、茶)都是有机物,理论上 NIR 也能识别。

但我们在实践中发现,污渍识别比面料识别更难:
- 光谱叠加问题:污渍是附着在面料上的,传感器接收到的光谱是 “污渍 + 面料” 的混合体。这就像我们要在一首嘈杂的摇滚乐背景(面料)中,听清歌手的低语(污渍)。
- 处理策略:我们需要针对不同的面料背景,建立不同的差分模型,或者训练模型去学习那种“叠加态”的特征。

目前,这部分工作正在紧张的样本采集和模型训练中,已验证可行。
六、 总结
这次项目的成功,给我最大的感触并非掌握了某项具体技术,而是解决问题的路径升级:
- 技术视野:当纯软方案走不通时,不妨把目光投向物理世界,跨学科的降维打击往往能产生奇效。
- 执行力:从对比 TI 与德国方案的成本,到去面料市场人肉采数,这些看似“非技术”的脏活累活,恰恰是技术落地的关键壁垒。
- 算法适配:不迷信复杂模型,针对特定数据特性(如光谱),经典的 PLS 算法反而比神经网络更高效、更可解释。