实战复盘:Qwen3 x ms-swift,在居住服务行业的微调实践
一、业务背景:复杂场景下的“时延争夺”
在我们的业务场景中,用户通过语音与平台交互,咨询租房、预约看房或了解详情。
我们要做的不仅仅是一个简单的分类任务,而是一个对时延和准确率都有着苛刻要求的实时系统。
1.1、苛刻的时延账本
领导层给出的死线是:端到端延迟控制在 2 秒以内。
这听起来似乎很宽裕,但我们必须为这 2 秒钟的“花销”精打细算。因为是语音交互,链路异常复杂:

ASR(语音转文字)和 TTS(文字转语音)这两个刚性环节就已经吃掉了 1 秒。
剩下不足 1 秒的时间窗口里,我们需要完成:
- 安全风控:输入输出的脱敏(集团合规要求)、防注入检测(toC 应用网信办备案要求)。
- 意图识别:判断用户是想咨询问题、找房、预约看房还是跳转视频等。
- 专家Agent:根据意图分发给具体的业务 Agent 处理(如搜索房源)。
逻辑推导:
意图识别是所有请求的“必经之路”。
如果这里使用庞大的基座模型(如 DeepSeek-V3 671B)或复杂的 RAG 架构,光是网络开销和推理就可能耗尽这 1 秒。
因此,我们需要一个极致轻量、响应极快的本地化模型。
1.2、80/20 的兜底策略
作为业务团队,我们还是更侧重于业务逻辑,所以不可能经常重新训练模型。
为了平衡“稳定性”与“灵活性”,我们在意图体系中特意设计了一个“其他”类别:
- 80% 高频场景(如预约、问答):由微调后的小模型(8B) 快速拦截,确保极低时延。
- 20% 长尾/新场景:归类为“其他”,透传给更强大的大参数基座模型(如 DeepSeek-V3)进行慢速但精准的处理。
这种架构既保证了核心体验的快,又兜住了边缘场景的准。
二、数据工程:用合成数据打破“偏置”
微调时很多人最关心的问题其实就是数据:数据不够怎么办?数据很脏怎么办?
说下我们的情况,我们的最终训练集只有 1000条出头。
这背后其实我们解决了两个核心痛点:
2.1、历史偏置与新场景
我们做了数据增强。
如果我们直接使用线上的历史日志训练,模型会“学坏”。
- 历史偏置(Bias):线上绝大多数数据都是“基础问答”,而“谈判”这类复杂交互样本极少(仅几十条)。如果直接训练,模型会倾向于把所有复杂请求都识别为简单问答。
- 冷启动(Cold Start):“视频跳转”是本次上线的新功能,历史上根本没有这类对话数据。
为了解决这个问题,我们利用 Self-Instruct 思路,用大模型合成了约 300+ 条针对性数据,强行“掰正”了模型的认知偏差,并教会了它新技能。
2.2、1000条够用吗?
经验之谈:
Garbage in, Garbage out. 在微调领域,数据质量的权重远远高于数据数量。
回到数据量级的问题上,我们的答案是可以,并且效果还不错。(详见后文效果)
对于特定领域的意图识别任务,我们的判断是:
- 简单任务:100-300 条高质量数据即可见效。
- 中等难度(如我们的意图识别场景):1000 条左右 清洗干净、分布均衡的数据,通常能达到很好的收敛效果。
- 高难度:需要 3000 条甚至万条级别。
相比于堆砌 1 万条充满噪音的脏数据,这 1000 多条经过人工校验和合成增强的“金数据”,才是模型效果质变的关键。
当然,我们对于训练数据的期许依然是越多越好的,因为越是充⾜的训练样本,可以更⼴泛的覆盖到各种各样的情况,能提升模型对于边缘情况的适配能⼒。
三、模型选型:8B
为什么最终定了 8B?
在项目初期,我们并没有直接锁定 8B 模型。而是秉持“实测说话”的原则,对 Qwen3 系列的 8B、14B、32B 三个尺寸进行了全方位的对比。
我们原本预期更大参数模型会有显著优势,但实践结果令人意外:在我们的特定业务数据下,8B 模型的表现与 14B、32B 几乎持平(详见后文效果对比)。
既然效果差异不大,考虑到推理成本和 QPS 的承载能力,8B 模型成为了性价比最高的选择。
四、技术栈选型:swift
4.1、为什么选择 ms-swift?
在微调框架的选择上,常用的 LLaMA-Factory 确实强大,也是一般的主流选择。
我们因为有一部分算力已经部署在阿里云集群上,我们就利用这次机会试用了 PAI 平台。
既然在 PAI 上跑,我们选择了阿里 ModelScope 官方出品的 ms-swift。
毕竟是“亲儿子”,在 PAI 环境中几乎零配置启动,且对 Qwen 系列新模型的适配速度极快。
4.2、关键训练参数复盘
在模型的训练过程中,参数的选择也是⼀⼤问题,此处我们参考实际过程中的训练脚本:
1 | |
对于其中⼀些参数做以下解释:
- 训练方式:
full(全参微调),需配合 DeepSpeed。 - 精度:
bf16。Qwen3 原生精度。 - 显存优化:开启
deepspeed zero3和flash_attn。这是在有限显存下跑通全参微调的关键,能显著降低显存占用并提升训练速度。 - 批大小:
per_device_train_batch_size 2配合gradient_accumulation_steps 2。这是一个典型的“空间换时间”的平衡。由于我们使用的是全参微调,显存压力巨大。如果单次塞入过多的样本(Batch Size 过大),很容易 OOM。因此,我们将单卡 Batch Size 压低到 2,通过 梯度累积(Gradient Accumulation)步数设为 2,在不更新参数的情况下累积两步的梯度,变相实现了 Batch Size = 4 的效果。这既保证了训练的稳定性,又避免了显存爆炸。 - 学习率:学习率设为
1e-5,学习率 warmup 占总步数的 5%。⼤模型常⽤初始学习率:1e-5~1e-4(AdamW 优化器),warmup 常用 0.05~0.1。
训练参数需要根据⼀些观测指标去进⾏动态的调整,ms-swift框架给我们提供了四种可观测指标,分别是:Loss、Token Accuracy、Gradient Norm 和 Learning Rate。
(1) Loss
⽤于衡量模型预测输出与真实标签之间的差异,是优化⽬标的核⼼指标。数值越低,模型预测越准确。 它反映了模型对训练数据的拟合程度。优化器通过反向传播最⼩化 Loss 来调整模型参数。
常⻅问题:
Loss 下降缓慢:可能学习率过低或模型容量不⾜。
Loss 波动剧烈:学习率过⾼或数据分布不均匀。
过拟合信号:训练 Loss 持续下降,但验证 Loss 停滞或上升。
相关函数:分类任务常⽤交叉熵损失(Cross-Entropy),回归任务常⽤均⽅误差(MSE)。
(2) Token Accuracy
在⼤模型任务中,模型正确预测的 token 占总 token 的⽐例。
它的作⽤是直观反映模型的语⾔理解或⽣成能⼒(如翻译、⽂本⽣成)。
需要与 Loss 结合分析,可发现模型是否“盲⽬追求准确率”(例如过度预测⾼频词)。
常⻅问题:
⾼准确率 ≠ ⾼质量⽣成(如⽣成语法正确但逻辑错误的句⼦)。
需结合其他指标(如 BLEU、ROUGE)或⼈⼯评估。
(3) Gradient Norm
梯度向量的 L2 范数,⽤于监控梯度更新的稳定性。
它反应的是模型参数变化的异动程度,表明模型是否还在进⼀步学习,以及学习的程度。
常⻅问题:
梯度爆炸:范数异常⼤(如 >1e3),可能导致参数更新失控。
梯度消失:范数趋近于 0,导致模型⽆法学习。
优化稳定性:正常训练时梯度范数应保持在⼀个合理范围内(如 0.1~10)。
应对策略:
梯度裁剪(Gradient Clipping):限制范数最⼤值(如 clipnorm=1.0)。
调整学习率:梯度范数过⼤时降低学习率。
(4) Learning Rate
控制模型参数更新步⻓的超参数,它直接影响训练速度和收敛性。
常⻅问题:
学习率过⾼:参数更新剧烈,导致 Loss 波动或发散。
学习率过低:训练缓慢,可能陷⼊局部最优。
动态调整:
学习率调度器:如线性预热(Linear Warmup)。
分层学习率:对模型不同层(如嵌⼊层、注意⼒层)设置不同学习率。
典型值:
⼤模型常⽤初始学习率:1e-5~1e-4(AdamW 优化器)。
预训练模型微调时:5e-5~3e-4(需根据任务调整)。
本次训练的真实指标变化:
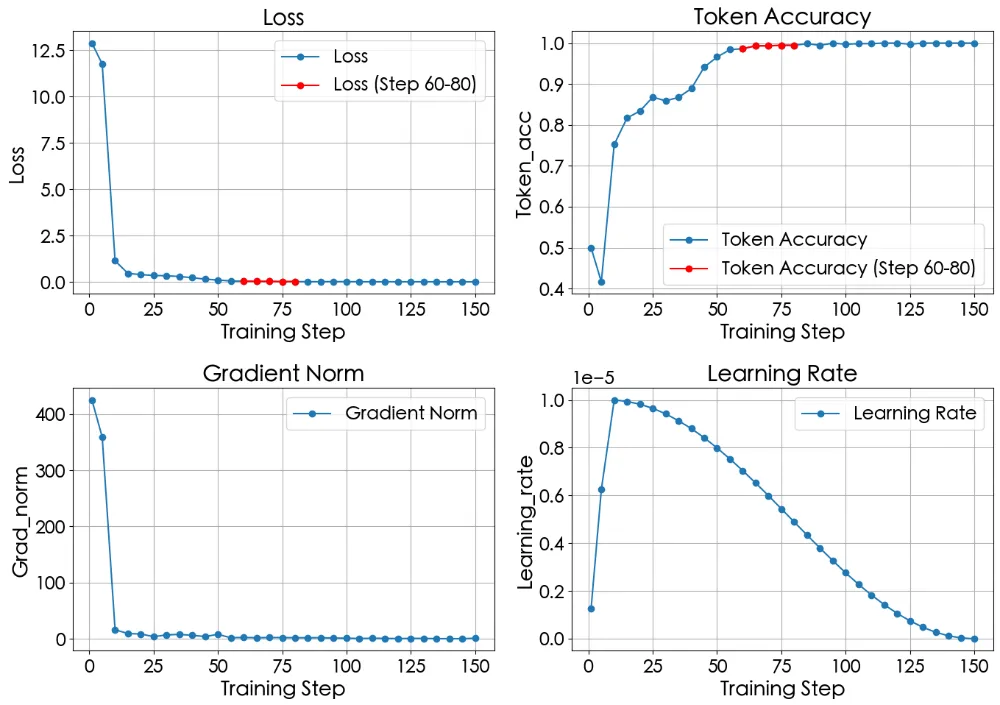
从图中我们可以看到:
在训练初期 Loss下降较快,随后进⼊缓慢收敛阶段,说明训练有效。
与 Loss下降趋势相对应,Token Accuracy 稳步上升,最终达到预期性能⽬标稳定在1附近。
Grad Norm 初期梯度下降较⼤,有助于快速更新参数 ,说明优化过程健康。
Learning Rate 使⽤ Warmup 学习率调度策略,学习率按预期变化⽆异常。
对于何时停⽌训练⽽避免过拟合的问题,我们应该考虑在 Loss 降到⼀个较低⽔平以后且 Token Accuracy 也达到了⼀个稳定状态之后停⽌训练,以避免或缓解过拟合的情况。
⽐如图中 step 在 60-80 之间的阶段就是⼀个合适的停⽌阶段,在这个阶段 Loss 和 Accuracy 刚到达了⼀个趋近于收敛的阶段,继续训练可能会有过拟合的⻛险。
判断过拟合的⼀个重要特征,其实是⽐较验证集和训练集的 Loss 差异,当有时候⼆者只能获得其⼀的情况下,可以通过上⾯的这种⽅式进⾏简单的判断。
另外值得⼀提的⼀点是,在学术上,过拟合是⼀种尽量需要避免的情况。
但是在实际应⽤中过拟合的情况并没有想象中的那么可怕,尤其是⼀些⼩模型的微调,模型训练之后只专注于⼀件事情(⽐如本次的意图识别),那么过拟合的情况就没有那么糟糕,只要模型的预测效果优秀,都是可以被业务拿来使⽤的“优质模型” 。
本次实践的训练是⼀个相对顺利健康的过程,⼤多数时候还可能会遇到其他⼀些情况:
1、Loss 不下降 / 不收敛 :Loss 在多个 epoch 或 step 后保持不变或波动很⼩。Token Accuracy 增⻓缓慢或停滞。Gradient Norm 可能趋近于零(梯度消失)或持续较⾼但⽆明显更新效果。
在⼤模型微调领域可能原因主要是学习率设置过⼩或过⼤。可以尝试调整学习率,尝试从1e-4开始逐步降低,并使⽤⼀些⾃动学习率调整策略,Warmup
+ Decay 等。
2、Loss 收敛但精度不⾼:Loss 明显下降并趋于稳定,但是 Token Accuracy 提升有限,⽆法达到预期⽬标。
可能原因:
- 模型尺⼨不⾜。
- 数据集噪声⼤或标签错误多。
- 正则化过强(导致模型⽋拟合)。
在⼤模型微调时⼤概率是前两个原因,因此可以考虑:
- 增加模型尺⼨;
- 清洗数据,去除异常样本,并且可能是业务上对于标签的定义不明确造成的,需要想办法制定合理的标签体系。
3、Loss 下降过程中出现突刺: Loss 曲线中出现突然上升的现象。Token Accuracy 可能随之波动。Gradient Norm 出现尖峰。
可能原因:
- Adam 优化器中浅层参数⻓时间未更新,导致梯度突变。
- batch size 设置过⼤,梯度更新过于剧烈。
- 梯度裁剪缺失或设置不当。
可以考虑使⽤梯度裁剪(Gradient Clipping)限制更新幅度或者调整 batch size ⾄合理范围。
4、训练初期收敛快后期停滞:初期 Loss 快速下降,Accuracy 提升明显。中后期 Loss 下降缓慢甚⾄停⽌。
可能原因:
- 学习率未随训练过程动态调整。
- 模型陷⼊局部最优或鞍点。
可以考虑引⼊学习率衰减机制(如 Step Decay、Cosine Annealing)。
五、最终效果:小模型的逆袭
训练完成后,效果的评估是很重要的环节,既能够评价当前模型的能⼒,同时也可以为后续进⼀步训练提升,提供参考价值。
我们本次的训练场景,显然是一个分类任务。因此我们采用 Accuracy(准确率),Weighted Precision(加权平均精准率),Weighted Recall(加权平均召回率)以及Weighted F1(加权平均F1值)这四个核⼼评价指标。
结果证明,针对特定领域,微调后的小模型完全可以吊打通用的超大模型。
5.1、核心指标对比
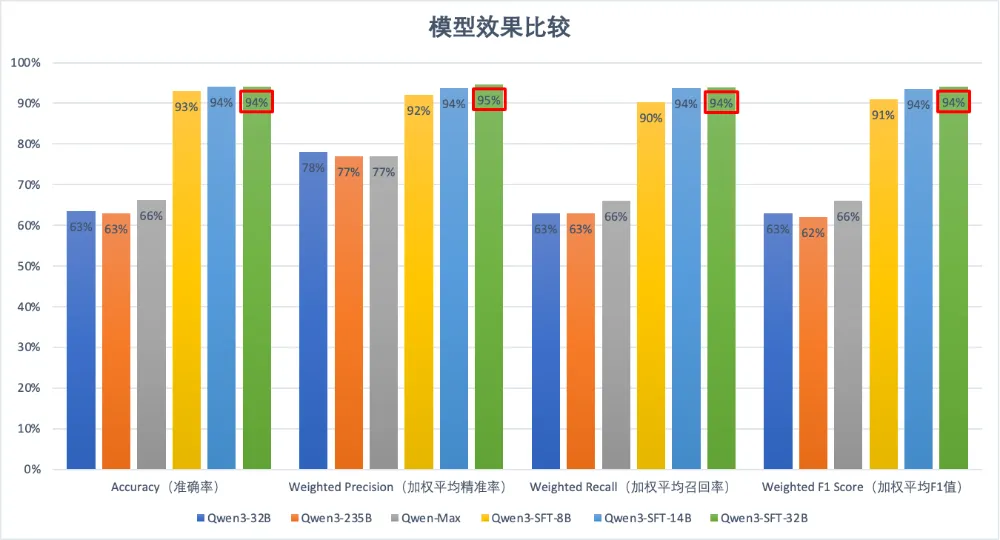
我们对比了 Qwen3-8B (SFT) 与基座模型 Qwen3-235B、Qwen-Max 的表现:
- Qwen3-Base (235B):准确率约 63%。
- Qwen-Max:准确率约 66%。
- Qwen3-SFT (8B):准确率飙升至 93%。
更进一步,我们对比了不同尺寸微调后的效果:
| 模型版本 | Accuracy (准确率) | Weighted F1 | 结论 |
|---|---|---|---|
| Qwen3-SFT-8B | 93% | 91% | 最终选择 |
| Qwen3-SFT-14B | 94% | 94% | 提升微小,推理成本翻倍 |
| Qwen3-SFT-32B | 94% | 94% | 提升微小,推理成本昂贵 |
图表解读:
从数据可以看出,经过 SFT 后,8B 模型的准确率相比未微调的超大基座提升了近 30%。而 8B 与 32B 之间的微调效果差距仅为 1%,但 8B 的推理速度和部署成本优势却是巨大的。
五类任务的常用评估指标:
- 分类任务
- 核⼼指标 :准确率(Accuracy)、F1值(尤其是类别不平衡时)、精确率(Precision)、召回率(Recall)、Hamming Loss(衡量标签预测错误率)。
- 补充评估 :⼈⼯校验分类结果是否符合业务场景需求(如医疗诊断需医⽣复核) 。
- ⽣成任务
- ⾃动评估 : ⽂本质量类的包括 BLEU、ROUGE、METEOR(衡量⽣成⽂本与参考答案的重合度)。 ⽂本 流畅度的指标如 语⾔模型困惑度(Perplexity)
- ⼈⼯评估 :需要考虑 相关性,检查 ⽣成内容是否贴合输⼊需求,如摘要是否涵盖原⽂重点;多样性, 输出是否存在⼤部分的重复,如对话回复是否灵活; 事实性 ,⽣成内容是否与现实⼀致。如历史事件描述是否正确,是否出现胡编乱造。
- 推理任务
- 逻辑推理 :准确率(看答案正确与否)、解决复杂问题的⽐例(如数学题的步骤完整性)。
- 多跳推理 :答案覆盖所有推理步骤的⽐例、与专家答案的⼀致性。
- 场景测试 :在真实场景中模拟⽤⼾提问,评估模型的实⽤性和鲁棒性,是否存在过于关注某⼀类任务,⽽导致了模型的泛化能⼒消失。
- 对话与交互任务
- 对话质量 : 主要考虑 连贯性 ,看模型回复是否与上下⽂逻辑⼀致,如在多轮对话中记忆⽤⼾偏好; 多样性, 回复是否避免模板化,如“好的” 、 “明⽩了”等重复表达。
- ⽤⼾满意度 :对于已经上线的业务,可以通过A/B测试或⽤⼾反馈评分,如NPS净推荐值。
- 任务完成率 :如客服场景中问题解决率、⽤⼾流失率等。
- 信息抽取任务
- 实体识别 :F1值,尤其关注低频实体的识别能⼒。
- 关系抽取 :准确率与⼈⼯标注的吻合度、对歧义关系的处理能⼒,如“苹果”是公司还是⽔果。
六、总结与 ROI 思考
通常 “高质量小数据 + 全参微调小模型” 在项目初期可能并不是一条 ROI 极高的路径。因为这需要专门的数据清洗、环境搭建和算力投入。
但我们的账是这样算的:
- 长期成本 vs 一次性投入:如果我们使用 DeepSeek-V3 或 Qwen3-235B 这样的超大模型(无论是 API 调用还是自部署),随着用户规模的扩大,推理成本是线性的、持续高昂的。而微调 8B 模型虽然有初期的一次性训练成本,但后续的推理成本极低(单卡 TPS 极高)。
- 确定性业务的规模效应:我们的业务场景是高度确定性的,投入前经过了严格论证。在千万级的调用量下,“微调小模型” 节省的推理算力,足以覆盖掉初期训练成本的数十倍。
这次实践证明:在确定性的垂直业务场景下,无需迷信大模型,采用 “小数据、小模型、精细化微调” 的路径,是企业级 AI 落地的一种 稳健、经济、规模化 的路径。