ELK 部署笔记
ELK 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK 具有如下几个优点:
- 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 Storm 那样预先编程才能使用;
- 配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
- 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
- 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
- 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
ELK Architecture
- Elasticsearch 是个开源分布式搜索引擎,与 Solr 类似,它隐藏了 Lucene 的复杂性。其特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,RESTful 风格接口,多数据源,负载均衡等。
- Logstash 是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用。
- Kibana 也是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助你汇总、分析和搜索重要数据日志。
Java Runtime Environment
因为 Elasticsearch 是基于 Lucene 用 Java 开发的, Logstash 是 JRuby 写的,所以你需要先配置一个 Java 运行环境。(Java 版本的最低要求是 Java 7,推荐 Java 8)
Elasticsearch
我所接触的主机都是 CentOS 系统的,所以这里就用 yum 安装了(图方便)。其他安装方式可参考 https://www.elastic.co/downloads 。
首先导入公钥数字证书
1 | |
添加 yum 源并安装
1 | |
安装完成后执行
1 | |
再测试一下是否启动成功
1 | |
如果返回以下结果则标明 ES 启动成功
1 | |
tips: ES 限制只能以非 root 用户启动。
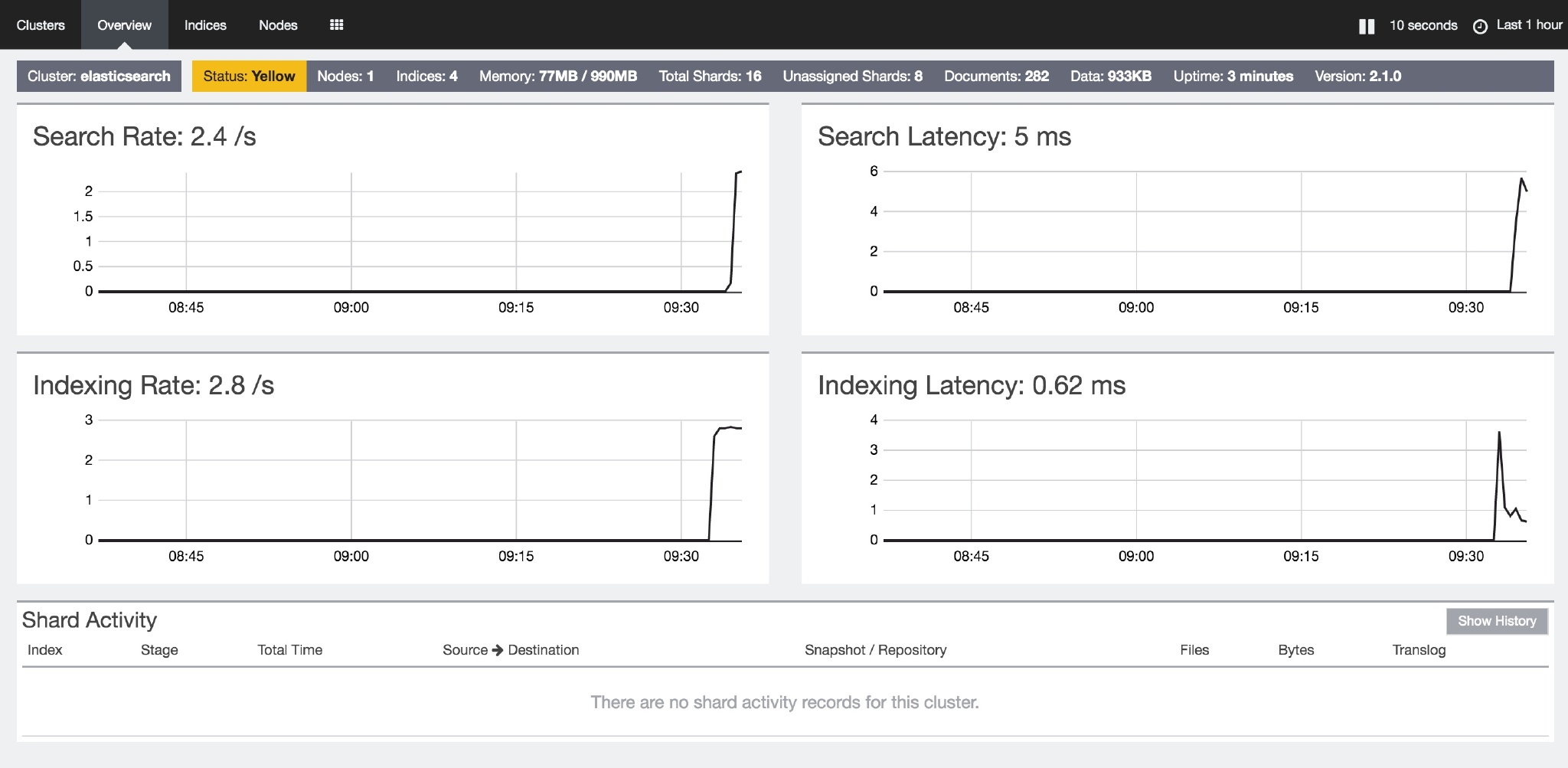
如果你想要一个监控界面来控制和了解 ES 的话,可以下载 marvel。Marvel是 Elasticsearch 的管理和监控工具,在开发环境下免费使用。它包含了一个叫做 Sense 的交互式控制台,使用户方便的通过浏览器直接与 Elasticsearch 进行交互。不过这个东西不能进行商用。另外一个可视化的插件是 Header,同样是一个 ES 的管理和监控的工具,不过它的功能稍微要少一些。
安装 Header 的话非常简单,直接在 es 的bin目录中执行sudo ./plugin install mobz/elasticsearch-head即可,它会自动的下载并解压安装包到plugins目录。
安装完成后,在浏览器中浏览http://host:9200/_plugin/head/
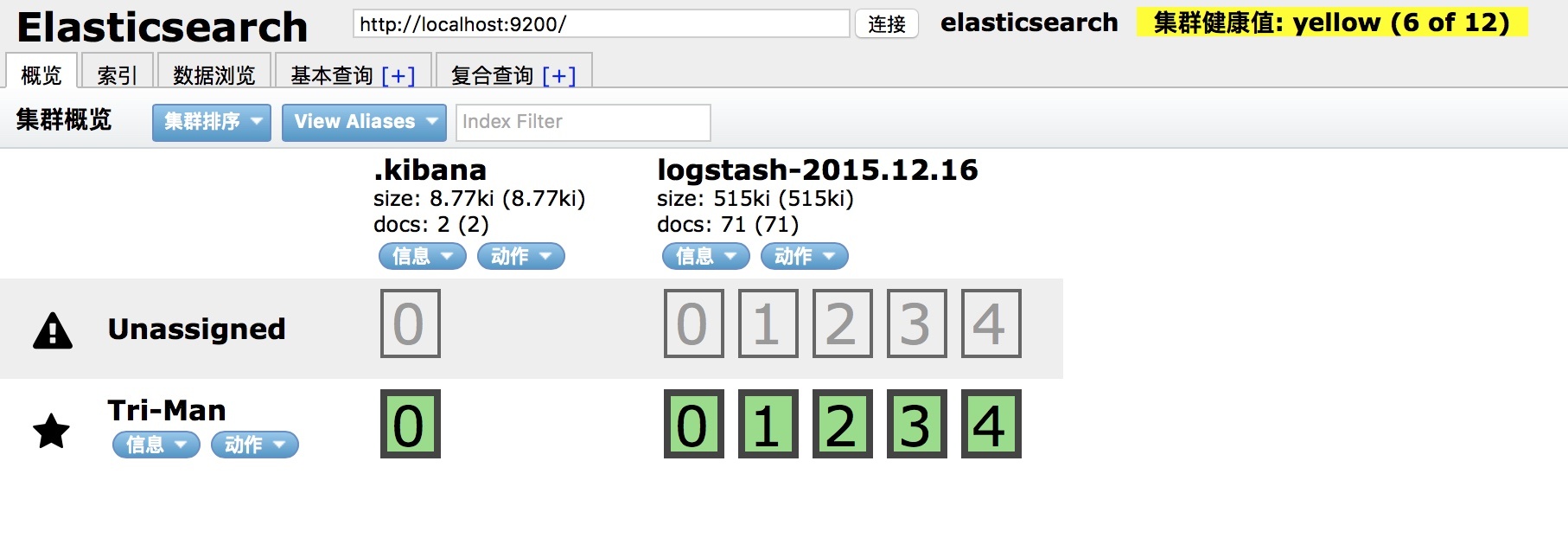
安装 Marvel 稍微要麻烦一点,最新的 Marvel2.X 需要依赖 Kiabana。首先需要安装 License 模块:./plugin install license,然后在 ES 中安装 marvel-agent:./plugin install marvel-agent,最后需要在Kiabana中安装 Marvel :./kibana plugin --install elasticsearch/marvel/latest
安装完成后,启动 Elasticsearch 和 Kiabana,然后在浏览器中浏览http://localhost:5601/app/marvel 即可。
相关阅读:
Elasticsearch: The Definitive Guide (英语不好可以参考这个中文版 )
Kibana
Kibana 的 rpm 包的版本还停留在 4.1.1 (目前官方最新的版本是 4.3.1),所以直接下载二进制包了。
1 | |
然后打开浏览器访问 http://host:5601 即可,Kibana 会自动的在 ES 中创建它自己所需的索引文件。
刚打开的时候会提示你创建 index pattern,但是这时候 ES 中其实还没有数据,这部分可以在配置好 Logstash 后再配置,这里先把步骤给出来:
- 这页按默认的就好,无需改动,直接 Create
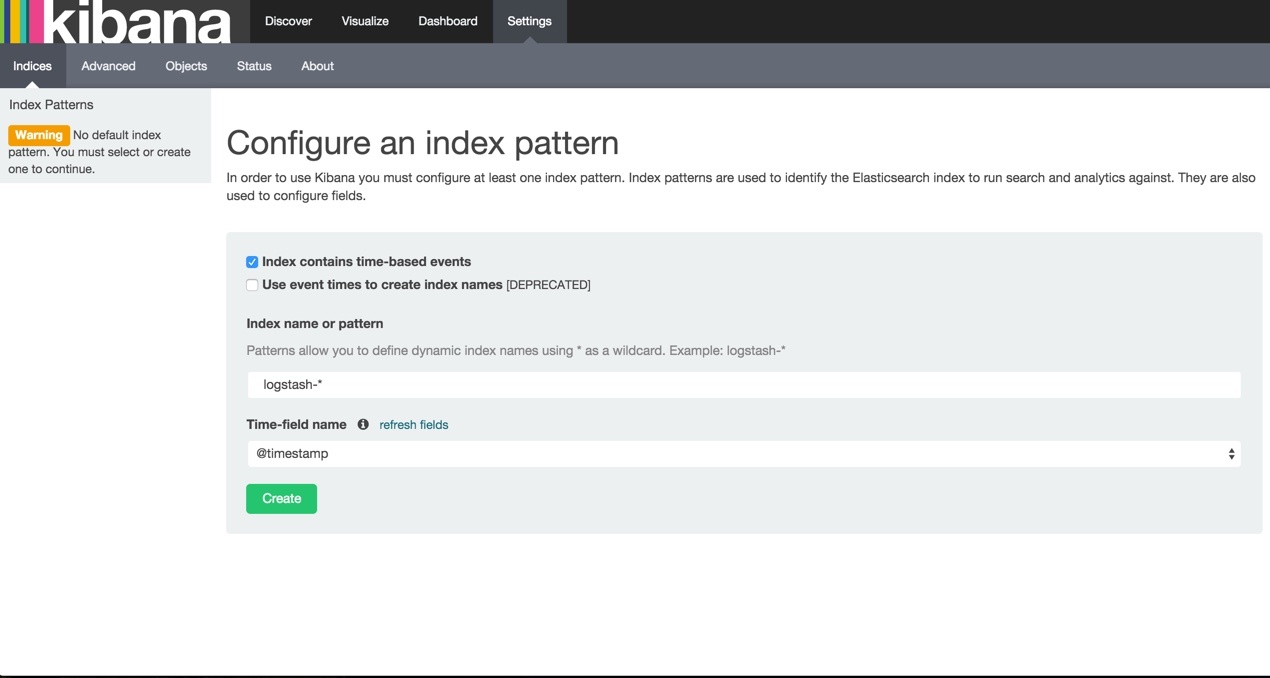
- 出现这个页面就说明配置成功了
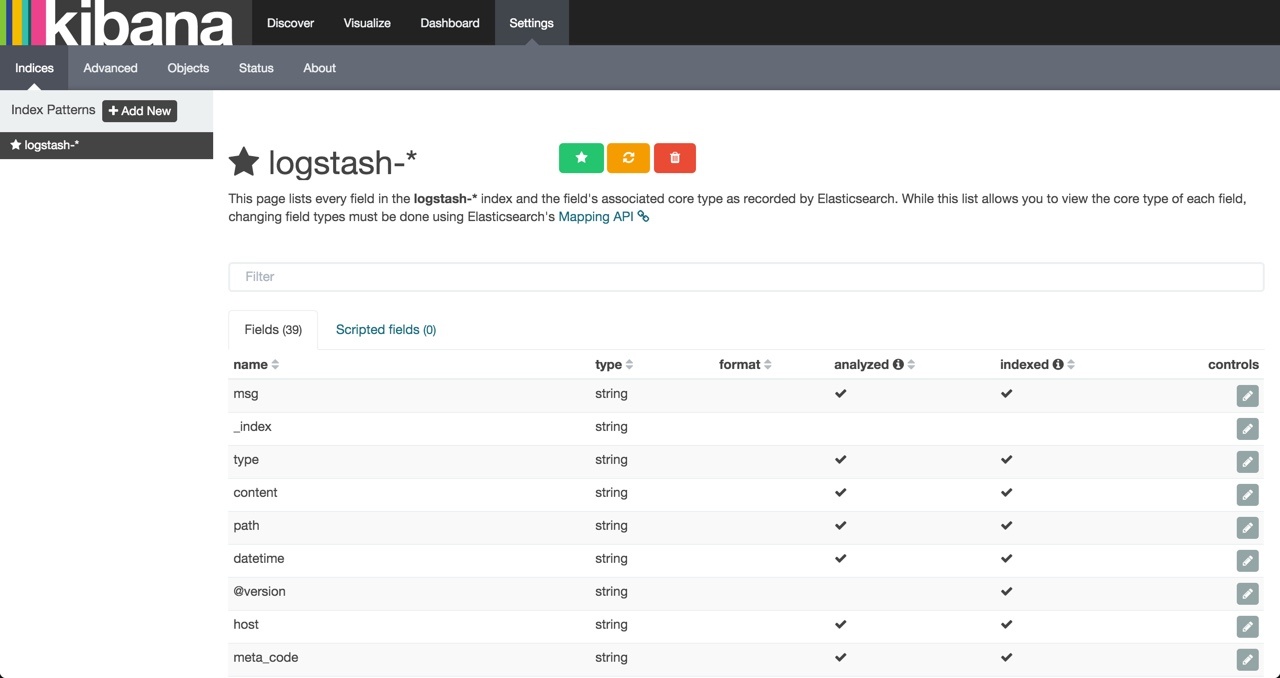
- 进入上方 navbar 的 Discover,就能看到数据并查询了
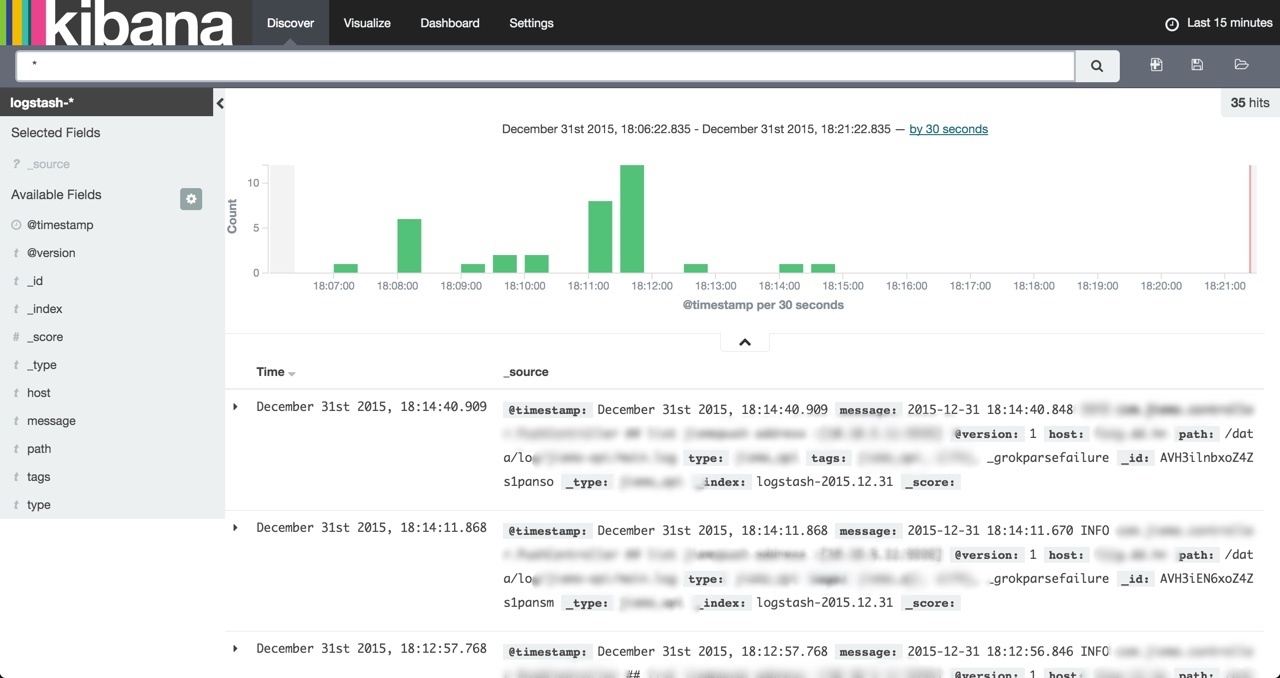
- 进入上方 navbar 的 Visualize,可以建立不同的图表以供分析
tips:如果你的 Kibana 和 Elasticsearch 不是在一台机器上或者之前你修改了 Elasticsearch 的默认端口9200,那么你需要在修改 Kibanaconfig/kibana.yml的elasticsearch.url。
Logstash
安装 logstash
1 | |
先测试一下
1 | |
提示缺少配置文件,那下边就要好好说说这个配置文件了。
tips: 这里也可能报错/etc/init.d/logstash: line 140: echo_failure: command not found,这是因为启动脚本有些问题,用 vim 打开/etc/init.d/logstash并在开头的位置添加
1 | |
Logstash 的日志采集过程主要有三个部分,分别是 _input_、 filter 和 _output_,分别对应了日志的收集、整理和输出。同时在 filter 的前后允许配置 _codec_,也就是编解码。每一个过程都提供了非常多的插件来辅助处理,具体有哪些插件可以查看这里。
比如最简单的一个 conf 文件
1 | |
它指定了日志采集的输入源为命令行输入,不经过任何的处理,输出源为控制台输出,输出的时候编码为 ruby 的 debug 格式。
执行这个采集的效果就是:
1 | |
再看一个复杂一点的例子(我用于测试环境中抓取 Java Web 服务的配置)
1 | |
这个配置用到了几个插件:
- input/file:从文件读取
- codec/multiline:多行合并——处理 Java stack traces
- filter/mutate:数据修改——特定字符转义
- filter/grok:正则捕获——匹配并标记异常的 message
- filter/throttle:节流阀——用于避免报警邮件爆满
- output/elasticsearch:保存进 Elasticsearch
- output/exec:调用命令执行——调用 mail 发报警邮件
该配置的简单解读:
- input 中监控两个本地 log 文件,并且给日志添加了一个
type属性用于在 filter 和 output 中区别来源。使用 codec 的 multiline 来将多行合并为一行(主要是处理像 Java stack traces 这样的,如果你的日志系统使用的是 Log4J,也可以使用 input/log4j 来处理)。最后指定 logstash 从什么位置开始读取文件数据。 - filter 中首先判断来源,然后舍弃掉空白符开头的行,将日志中 ‘ 替换为 `(因为它会干扰到邮件报警),使用 grok 匹配异常并标记,之后判断是否是异常信息,如果是,则经过 throttle 进行节流处理。
- ouput 中首先输出到 Elasticsearch,然后判断是否异常,异常则发邮件报警。
tips:
- 可以在 grok 中写普通的正则,不过更优雅的做法是把预定义的 grok 表达式写入到文件中,logstash 已经内置一些预定义 grok 表达式,对于自己写的 grok 表达式,我建议你使用 Grok Debugger 来调试。
- 文档中说 filters/grok 插件的
match参数应该接受的是一个 Hash 值。但是因为早期的 logstash 语法中 Hash 值也是用[]这种方式书写的,所以向我上边那样传递 Array 值给match参数也完全没问题。这样就实现了多项匹配,logstash 会按照这个定义次序依次尝试匹配,到匹配成功为止。虽然效果上和在正则中使用|的效果是一样的,不过这样可读性更佳。
到此, ELK 平台部署和基本的测试已完成。