Deep Search 与 Deep Research
2022 年 11 月 30 日,OpenAI 正式发布 ChatGPT 产品,仅两个月后,其月活用户就突破了 1 个亿,成为历史上增长最快的消费类应用之一。一时之间,生成式 AI 技术遍地开花,国内外科技大厂紧锣密鼓纷纷入场,各种大模型和 AI 产品以星火燎原之势涌现出来。
ChatGPT 的发布对传统搜索(如 Google)和问答社区(如 StackOverflow)造成了强烈的冲击。用户对传统搜索的不满早已不是秘密,搜索结果中大量的广告和低质的 SEO 内容导致用户体验很差,而 ChatGPT 通过自然语言以对话的方式为用户直接提供答案,省去了用户在海量的搜索页面之间反复跳转和搜集信息的麻烦。谷歌拥有 DeepMind 和 Google Brain 两大顶尖 AI 实验室,原本有机会站在这波生成式 AI 浪潮的最顶端,但是管理层安于现状,不忍放弃广告业务的利润,最终被 ChatGPT 抢占先机。为了应对 ChatGPT 的冲击,谷歌很快开始了反击,公司在内部发布 红色代码(Red Code) 预警,进入战备状态,创始人布林甚至亲自下场为聊天机器人 Bard 写代码。
生成式 AI 和传统搜索之间的战争就此拉开了序幕。
AI + 搜索
不过很快人们就发现了 ChatGPT 的不足,尽管 ChatGPT 能以简洁的交互给出即时答案,但是它的答案中充斥了大量的事实性错误,幻觉问题和静态知识是大模型天生的两大局限,导致其答案准确性达不到搜索引擎的要求。一开始,大家只是作为谈资一笑了之,但是随着大模型在商业化应用中的落地,人们的抱怨声也就越来越多,在某些场景下,比如医疗建议,错误的回复可能导致灾难性后果。
为了解决这些问题,又一项新技术应运而生,那就是 RAG(Retrieval-Augmented Generation,检索增强生成),通过引入外部信息源,包括搜索引擎、企业私域知识、个人笔记等一切能查询的信息,可以有效的缓解大模型的幻觉问题,在生成答案时还可以标注信息来源以提升可信度。
2024 年 10 月,ChatGPT 推出搜索功能:
国内外产商也纷纷跟进,比如 DeepSeek 的:
Qwen Chat 的:
Kimi 的:

前不久,Claude 也集成了搜索功能:
如今 AI + 搜索 已经是各家大模型产品的标配。
与此同时,搜索 + AI 也不甘示弱,比如 Google 面向美国用户推出的 AI Overviews 功能,在搜索结果顶部提供自然语言生成的答案摘要;百度在搜索顶部也加入了 AI+ 功能:
还有一些比较小众的搜索服务和开源项目,比如 YOU.COM、iAsk、Lepton Search 等,感兴趣的也可以尝试下。
技术原理
AI + 搜索 的本质是 朴素 RAG。
RAG 的基本流程,如下图所示:
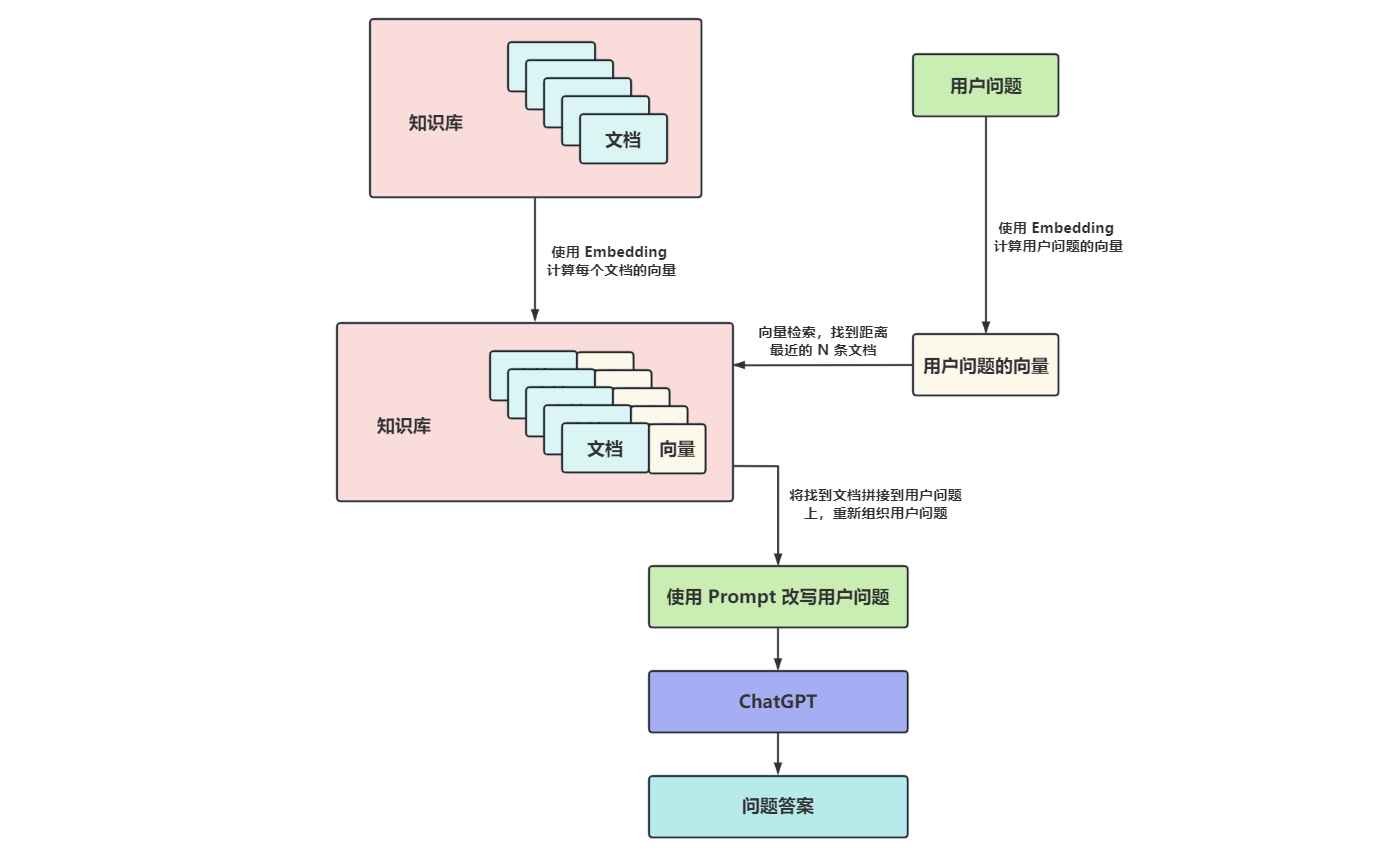
可以看出它的实现非常简单,唯一的难点是知识库文档和用户问题的向量化以及向量检索,而 AI + 搜索 则更简单,直接拿着用户问题去调搜索引擎的接口就行了:
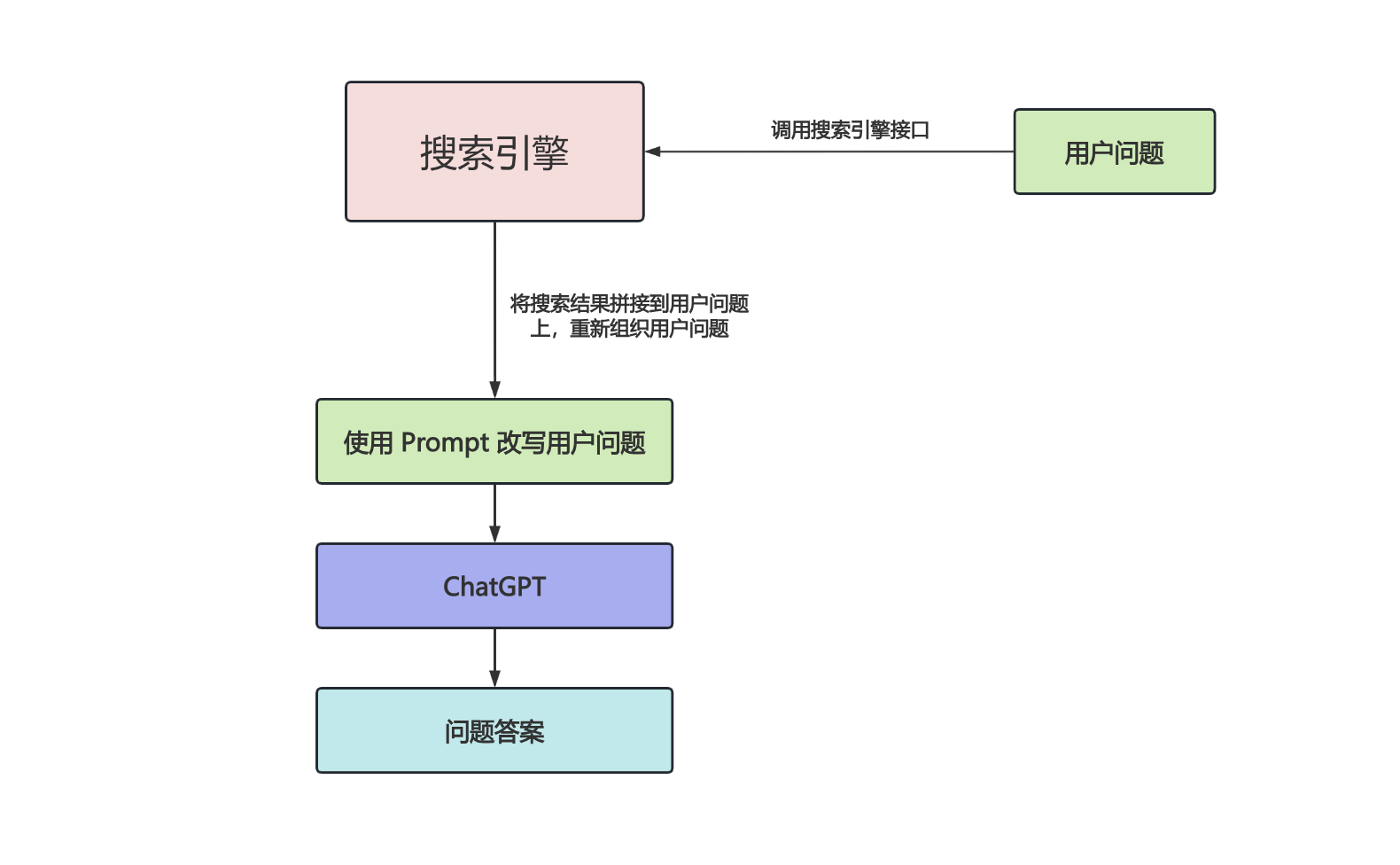
关于如何组织搜索结果和用户问题,可以参考 DeepSeek 公开的 Prompt:
1 | |
这里最大的难点可能不是技术问题,而是去哪里找免费的搜索引擎接口?下面是搜集的一些常用的搜索服务:
- Bing Web Search API - 每月 1000 次免费调用
- Google Programmable Search Engine - Google 的自定义搜索
- SearchApi Google Search API - 注册送 100 次调用
- Serper API - 注册送 2500 次调用
- Serp API - 每月 100 次免费调用
- Brave Search API - 每月 2000 次免费调用
- Exa API - 注册送 $10 额度
- YOU API - 60 天免费使用
- Tavily - 每月 1000 次免费调用
- 博查搜索 API - 国内不错的搜索服务,不免费,但确实便宜,一次调用 3 分钱
除了这些通用搜索服务,还有一些领域类搜索,比如学术搜索可以用 Google Scholar API、arXiv API 等;本地商业搜索可以用 Yelp Fusion API、高德地图 API 等。
此外还可以使用诸如 Meilisearch 这样的开源项目,自建本地搜索引擎,完全免费,这非常适用于用户自有数据。
AI + 深度搜索(Deep Search)
朴素 RAG 的弊端很快便浮现了出来:RAG 中最核心的问题是 R,也就是检索,在面对模糊问题时,检索结果的精确性往往不高,面对复杂问题时,单次检索又不足以获取足够的上下文信息;为了解决这些问题,人们又提出了 高级 RAG 和 模块化 RAG 等概念,通过 查询重写(Query Rewriting)、查询扩展(Query Expansion) 等方法将用户的原始问题转换成更清晰、更适合检索的任务,这种方法也被称为 查询转换(Query Transformation):
![]()
在过去的一年里,RAG 技术日新月异。
Graph RAG
尽管如此,传统 RAG 在面对更复杂的问题时仍然是捉襟见肘,这些问题往往需要更深入搜索和推理,具体包括:
- 全局性问题理解:传统 RAG 主要依赖向量检索,擅长回答局部的、具体的问题,但难以处理需要跨文档推理的全局性问题;
- 近五年人工智能领域的论文中,哪些研究方向的热度增长最快?
- 复杂语义关系问答:传统 RAG 忽略了实体间的语义关系,导致回答缺乏逻辑连贯性;
- 《哪吒2》是哪个公司发行的,这个公司还发行过哪些票房超10亿的电影?
- 多跳推理问题:传统 RAG 无法处理需要多步推理的问题,因为向量检索仅返回单篇文档片段;
- 《哪吒2》中哪吒配音的老家天气怎么样?
- 复杂条件筛选:依赖关键词匹配可能漏检,无法处理复合逻辑条件;
- 找出所有总部在加州、员工超过1万人,且创始人毕业于斯坦福的科技公司。
2024 年上半年,微软公开了 Graph RAG 的论文 From Local to Global: A Graph RAG Approach to Query-Focused Summarization,将知识图谱的概念引入 RAG 中,通过结构化信息提升大模型生成内容的准确性、相关性和可解释性。在年中的时候,Graph RAG 正式开源,在社区引起了相当的热度,在很短时间内就超过了上万星标。
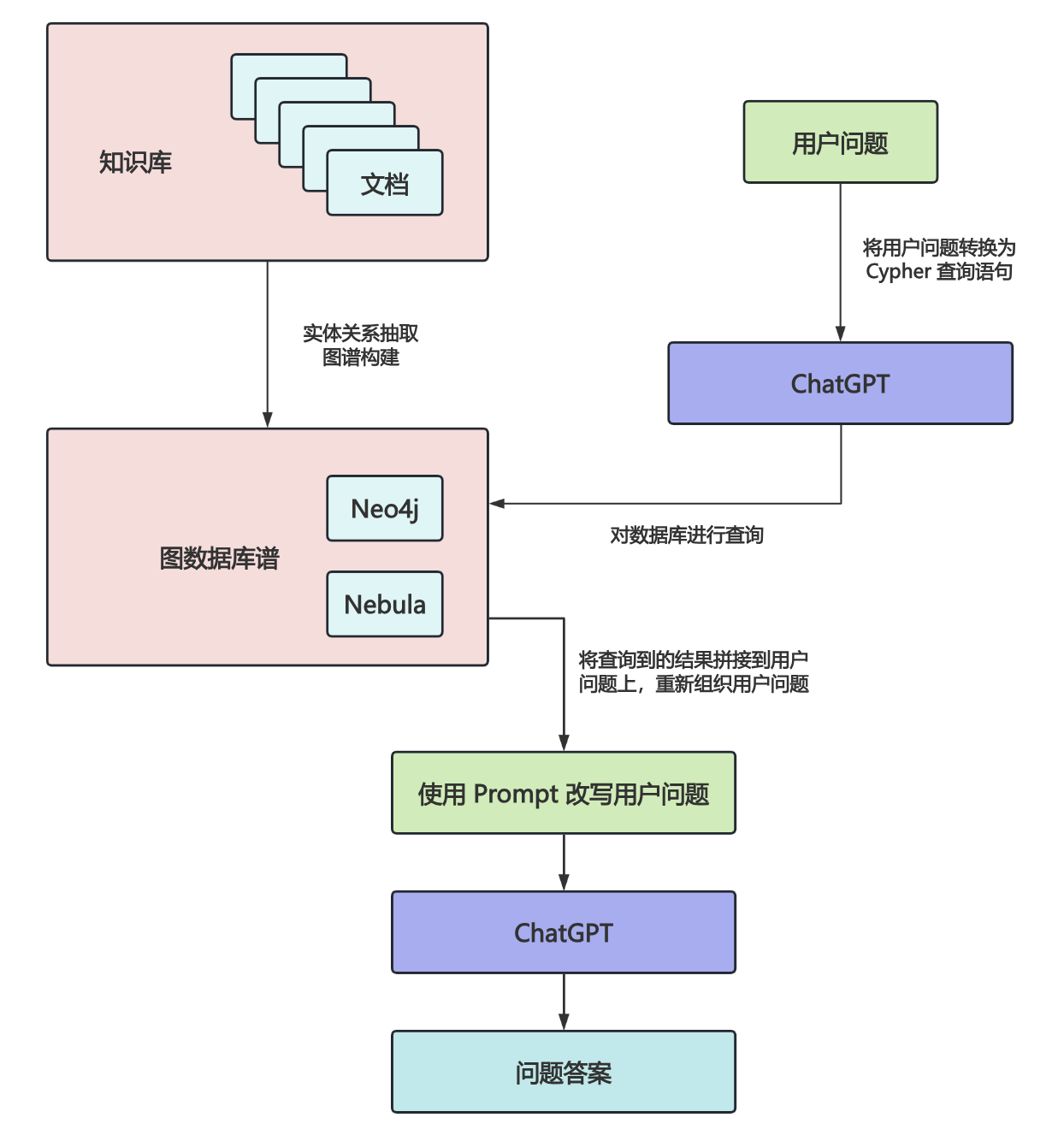
Agentic RAG
上面这些 RAG 的流程基本上都是线性的,遵循着 检索-生成-结束 这样的固定流程。后来,随着智能体的兴起,又出现了 Agentic RAG 的概念,这是传统 RAG 的进阶范式,将智能体的任务规划、工具使用、反思重试等机制引入 RAG 流程中。
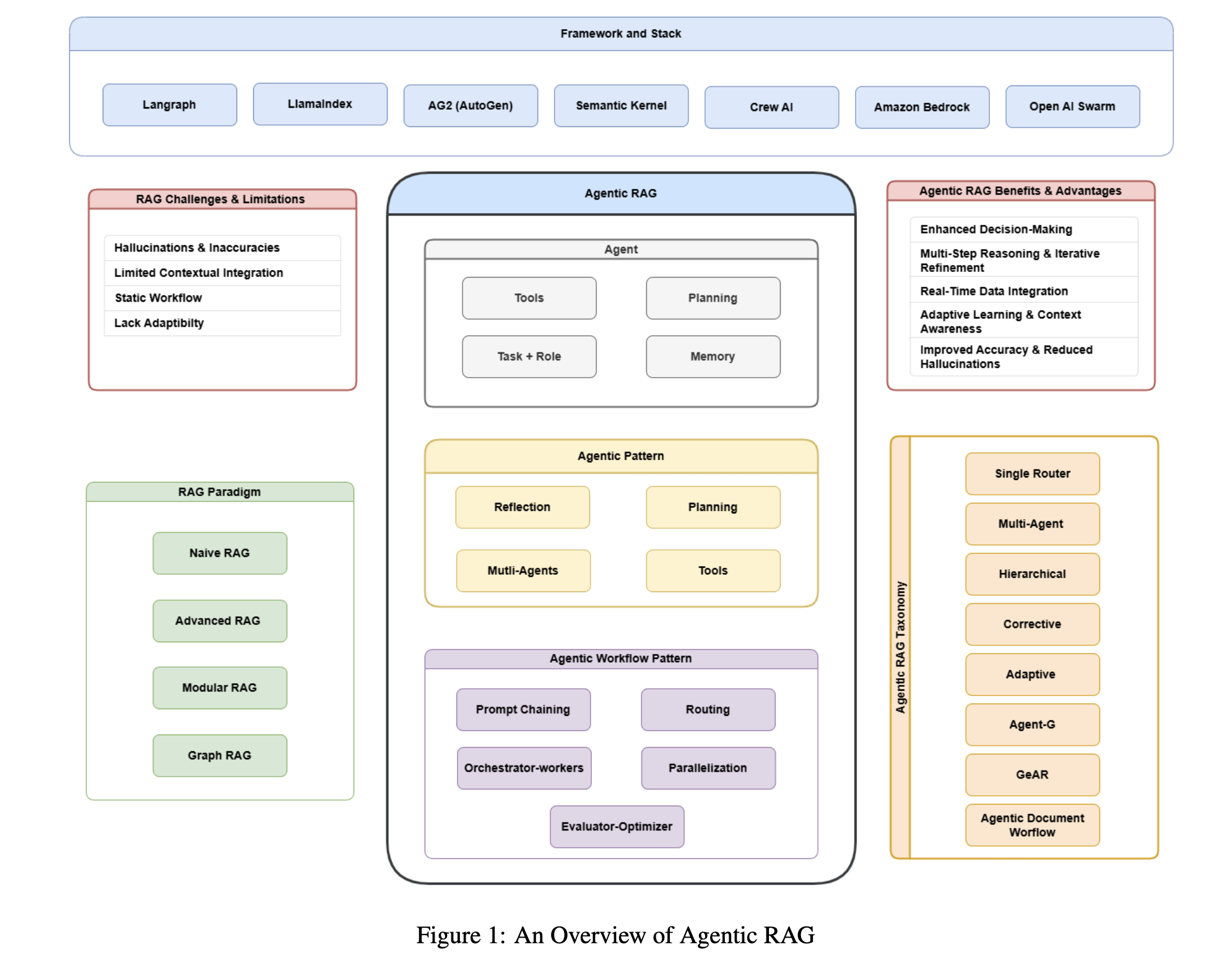
智能体的核心是 思考-行动-观察 循环,这三个组件在一个持续的循环中协同工作,从而实现智能体的自主性、交互性和决策能力。将智能体引入 RAG 系统,可以让其具备更动态、更灵活的检索与生成能力;最直观的表现就是反复的检索,比如切换不同的数据源(工具使用),切换不同的检索词(子任务拆解、反思),直到用户问题解决为止。
Agentic RAG 的典型能力如下:
- 动态检索:根据生成内容的中间结果,决定是否需要二次检索,发现答案不完整时自动触发新搜索;或者根据问题类型主动选择检索源,比如优先查数据库还是通用搜索引擎;
- 任务分解:将复杂问题拆解为子任务,比如用户的问题是 “对比 A 和 B”,那么需要先检索 A 的特性,再检索 B 的特性,最后综合比较;
- 工具调用:让 RAG 不仅仅局限于检索,也可以调用外部工具获取实时信息,比如查询股票价格和天气情况;又或者执行计算或生成代码,比如通过 Python 代码分析数据,再生成结论;
- 反思与修正:对生成结果自我评估,发现不足时重新检索或调整生成策略,比如在生成报告时发现缺少某部分数据时能自动补充;
- 多轮交互:在对话中主动追问用户以澄清需求,比如用户的要求是 “帮我找一些关于人工智能的论文”,可以追问要找的是什么领域,是 NLP 还是计算机视觉。
有很多关于 Agentic RAG 的开源实现,比如 LlamaIndex、LangGraph、smolagents 等教程。
Deep Search
接下来,我们再来看下什么是 深度搜索(Deep Search)?其实,目前学术界并没有这个概念的明确定义,只是有几个产品或开源项目是以这个命名的,比如 Grok 3 中推出的 DeepSearch 和 DeeperSearch 功能:
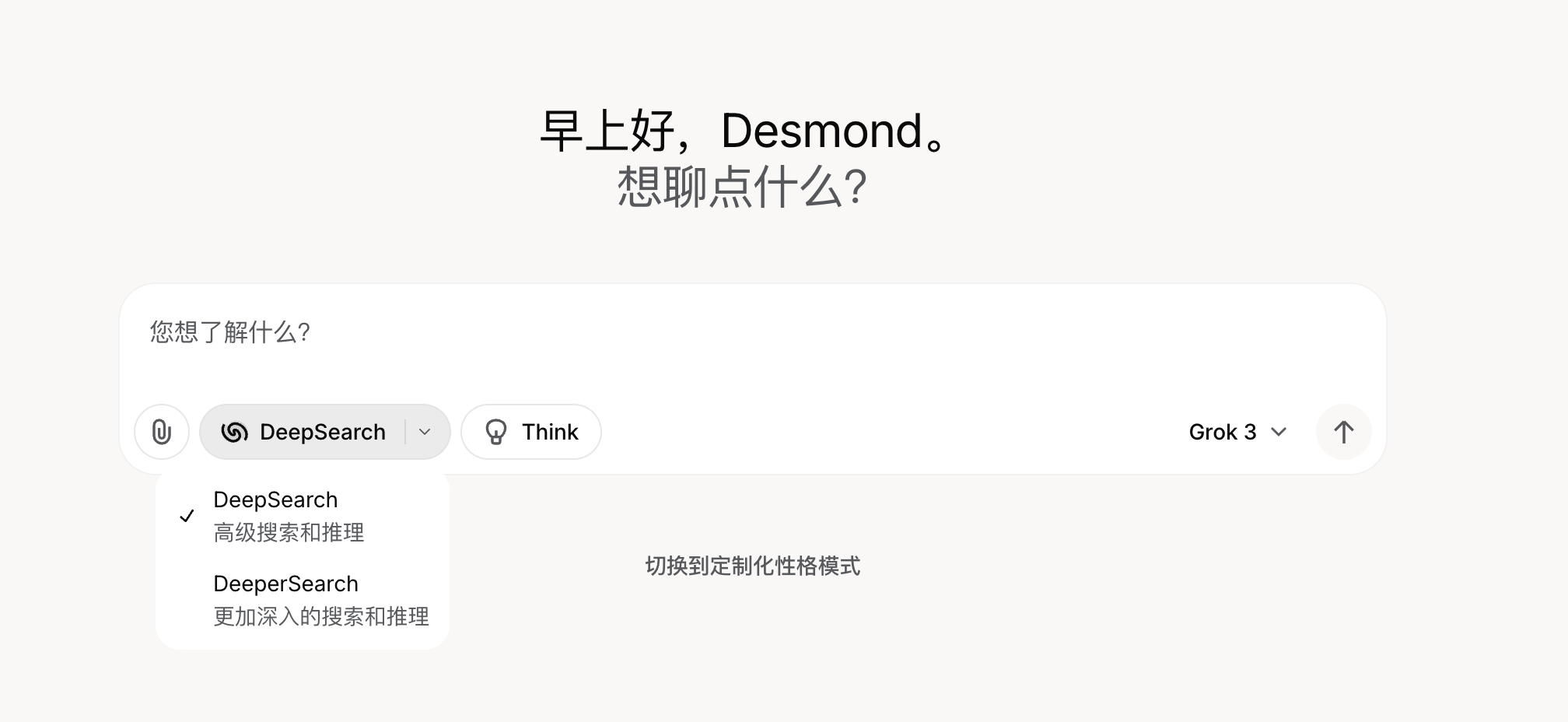
在回答问题时会经过 思考-搜索-分析-验证 等步骤:
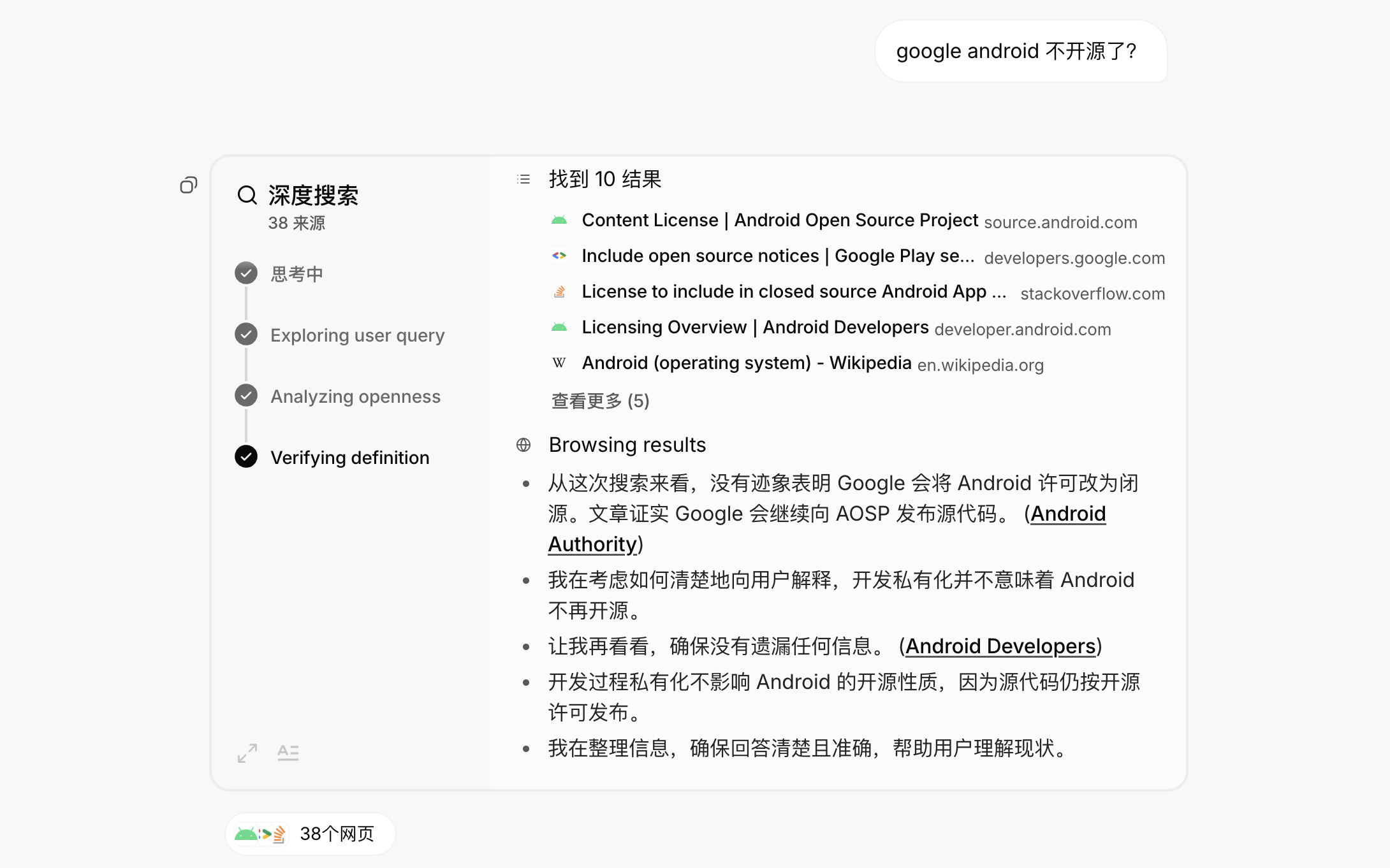
这和上面的 Agentic RAG 使用的 思考-行动-观察 循环如出一辙,所以本质上来说,Deep Search 就是 Agentic RAG。
另一个是 Jina AI 推出的 深度搜索 API 服务,它会对用户的问题进行广泛搜索并经过多次迭代,然后给出答案。
这个 API 和 OpenAI 的接口基本一致,所以很容易接入我们的应用中,官方也提供了 对话页面 可以体验。同时,这还是一个开源项目,项目名叫 jina-ai/node-DeepResearch,虽然名称里有 DeepResearch 但是实际上它只有 DeepSearch 的功能,感兴趣的同学可以去扒一扒它的源码,官方还贴心地写了两篇公众号文章对其实现原理做了详细的讲解,推荐一读:
还有一个是 Zilliz 公司(就是开源 Milvus 向量数据库的那家公司)开源的项目 zilliztech/deep-searcher:
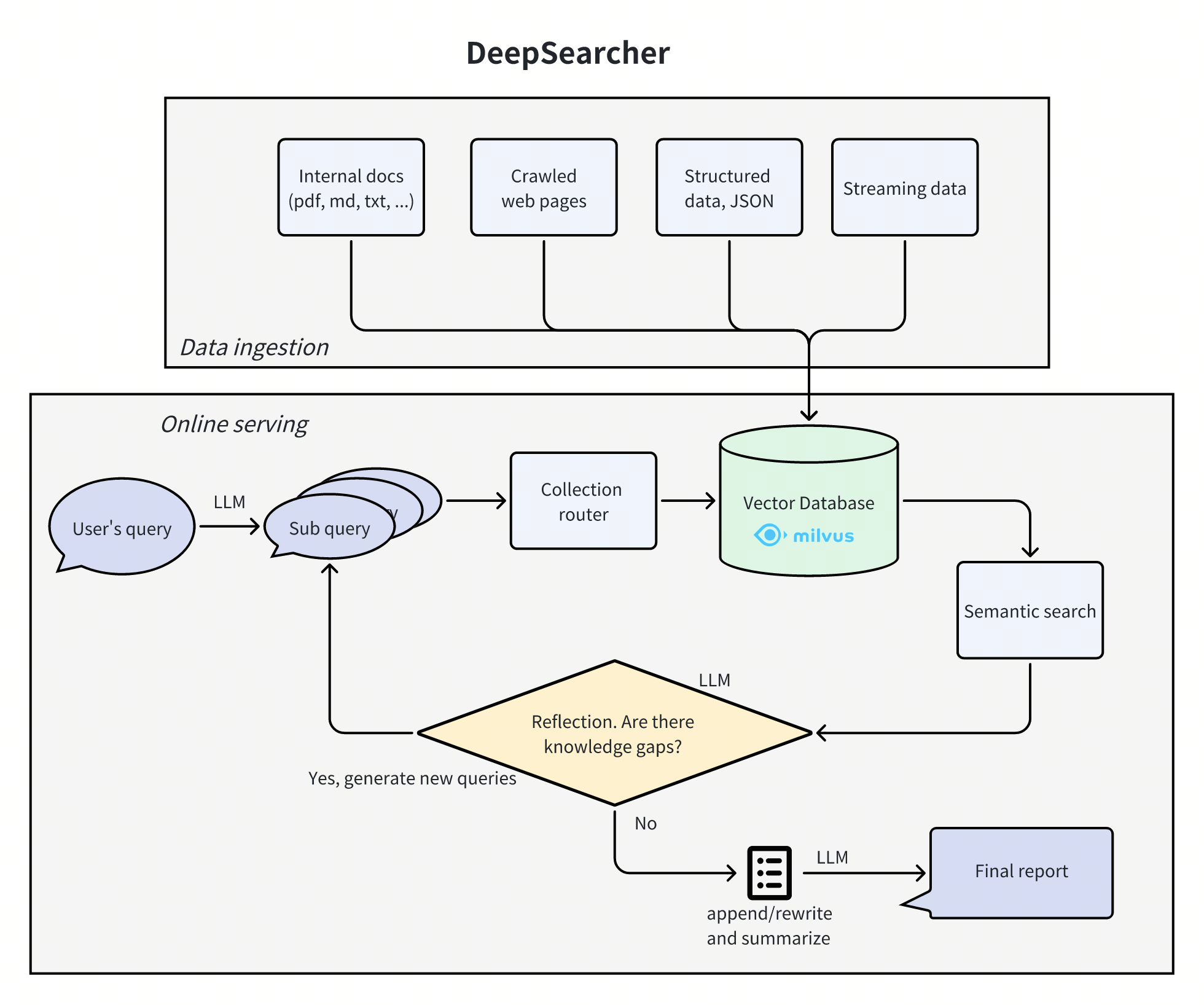
细读它的源码可以发现,它主要分为两个部分:
- 离线数据处理:通过各种
file_loader和web_crawler加载文件和网页,切片后生成向量,构建离线数据;其中web_crawler使用了 Jina Reader、Firecrawl、Crawl4AI 等接口实现网页内容的爬取; - 在线实时问答:代码中实现了两个 Agent,根据问题的类型路由到对应的 Agent 来处理:
- ChainOfRAG:这个 Agent 可以分解复杂的查询,并逐步找到子查询的事实信息,它非常适合处理具体的事实查询和多跳问题;
- DeepSearch:这个 Agent 适合处理一般和简单的查询,例如给定一个主题,然后撰写报告、调查或文章。
下面是一个粗略的流程图:
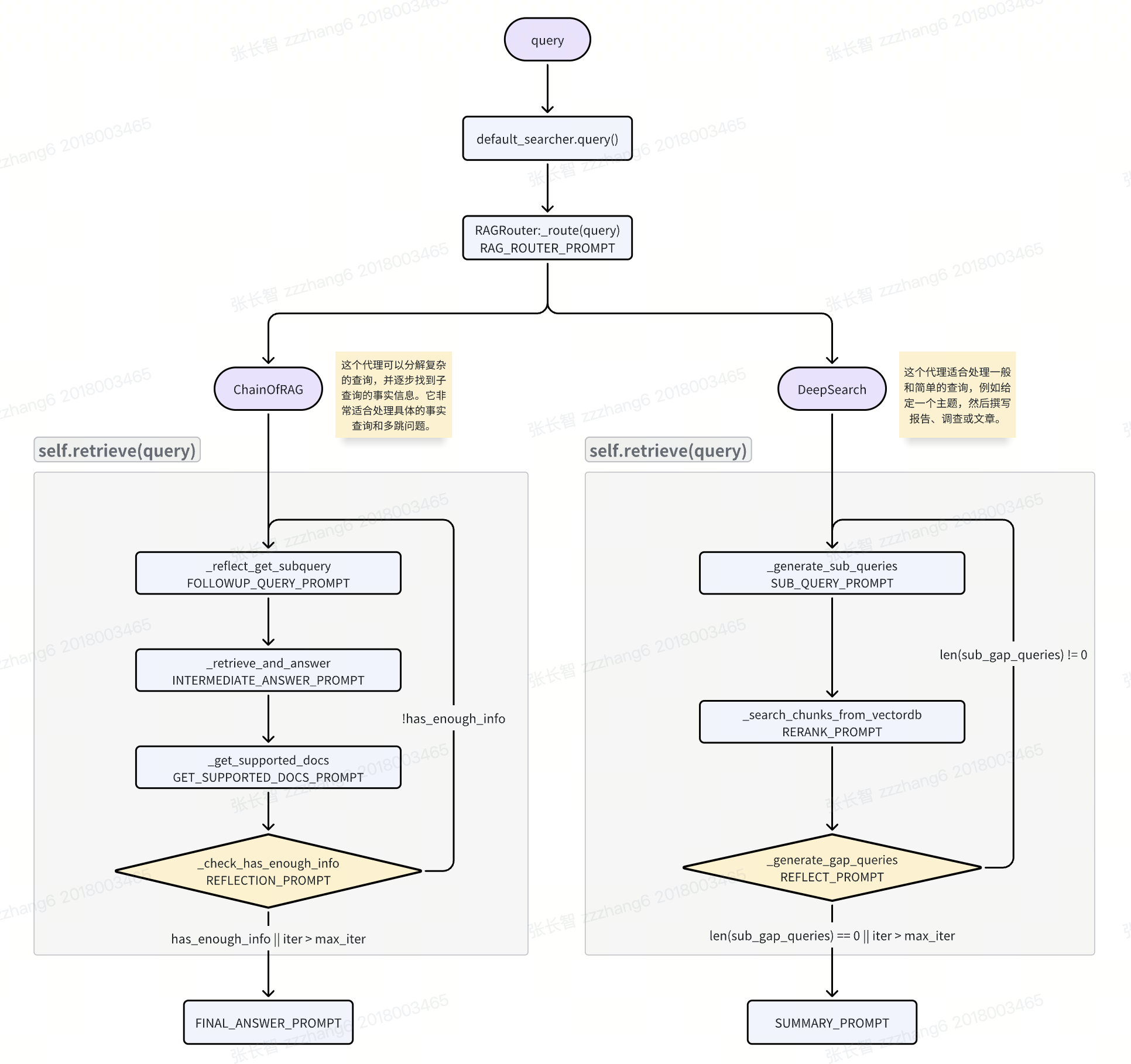
其中 ChainOfRAG 借鉴了 Chain-of-Retrieval Augmented Generation 这篇论文中的思路。可以看到两种 Agent 都具备 Agentic RAG 循环的特点,循环里的每一步都是通过调用大模型来实现的,使用了不少的 Prompt 技巧。
和 Jina AI 的 node-DeepResearch 项目对比一下可以发现,Zilliz 的 deep-searcher 依赖于向量数据库,着重聚焦于对私有数据的深度检索。虽然两者都有使用 Jina Reader 接口,但是 node-DeepResearch 是作为搜索接口,用户对话时实时请求,而 deep-searcher 是用来构建离线数据。另外,Zilliz 也发布了几篇公众号文章,不过其标题和内容颇具争议,在网上引发了不少的讨论,也可以参考下。
AI + 深度研究(Deep Research)
其实,深度搜索早已不是什么新鲜概念,早在两年前就有不少产品提供类似的功能,比如 天工 AI 搜索,号称 “国内第一款AI搜索产品”,于 2023 年 8 月就已经上线了:
再比如国内的 秘塔:
国外的 Perplexity:
他们都是在大模型兴起之初就开始 AI + 深度搜索 这方面的研究了,那为什么到今天,这个概念才开始引起各方的关注呢?
Deep Research 演进历史
我们不妨梳理和回顾下 AI 圈近几个月发生的一些重要事件:
- 2024 年 9 月,OpenAI 发布 o1-preview,该模型在回答之前会花更多时间思考,使其在复杂推理任务、科学和编程方面显著优于其他模型;
- 2024 年 10 月,Anthropic 推出 Computer Use 功能,使 AI 能像人类一样操作电脑,通过观看屏幕截图,实现移动光标、点击按钮、使用虚拟键盘输入文本等操作,真正模拟人类与计算机的交互;
- 2024 年 12 月 11 号,Google 发布 Gemini 2.0 Flash,同时还给 Gemini 带了一项名为 Deep Research 的新能力,利用高级推理和长文本处理能力,Deep Research 可以充当个人的研究助理,比如用来做一些复杂的研究报告;
- 2024 年 12 月 19 号,Google 紧接着又发布了 Gemini 2.0 Flash Thinking 公开预览版,这也是一种思考模型,可以在模型生成回答时查看其思考过程,并生成具有更强推理能力的回答;
- 2025 年 1 月 20 号,深度求索的 DeepSeek-R1 横空出世,用极低的成本达到了比肩 OpenAI o1 的水平,在全球市场上掀起了一股前所未有的热潮,也潜移默化地把 “推理模型” 这个概念带给了千家万户,将思考过程渲染在聊天界面已经变成了一种标准做法;
- 2025 年 1 月 23 号,OpenAI 发布 Operator 智能体,和 Anthropic 的 Computer Use 类似,可以操作浏览器,为用户执行各种复杂任务;
- 2025 年 2 月 2 号,OpenAI 又发布了 Deep Research 功能,它可以自动搜集大量的网络信息,利用推理能力综合分析,为用户完成更为复杂的研究任务,能在几十分钟内完成人类需要数小时才能完成的工作;
- 2025 年 2 月 14 号,Perplexity 紧随其后,同样也发布了 Deep Research 功能,能够执行多次搜索、阅读大量来源并生成全面报告;
- 2025 年 2 月 19 号,xAI 推出 Grok-3,内置 DeepSearch 和 DeeperSearch 功能;
- 2025 年 2 月 25 号,阿里 Qwen 团队发布推理模型 QwQ-Max-Preview,它基于
Qwen2.5-Max构建,在数学、编程以及通用任务中展现了更强的能力,同时在 Agent 相关的工作流中也有不错的表现; - 2025 年 3 月 5 号,Google 面向 Google One AI Premium 订阅用户推出 AI Mode 功能,提供对话式搜索体验,支持复杂多轮提问;
- 2025 年 3 月 6 号,中国 AI 创业公司 Monica 发布 Manus,号称 “全球首款通用 AI 代理”,其应用场景覆盖旅行规划、股票分析、教育内容生成等 40 余个领域;据称,Manus 在 GAIA 基准测试中刷新了 SOTA 记录,性能远超同类产品,凭借 KOL 助力,一时间刷屏全网,内测邀请码一码难求,甚至被炒到 5 万块钱;
- 2025 年 3 月 31 号,在中关村论坛智谱 Open Day 上,智谱发布了 AutoGLM 沉思,这又是一款 Deep Research 类智能体,它能够模拟人类的思维过程,完成从数据检索、分析到生成报告的全过程;
可以看出 2025 年刚过去四分之一,Deep Research 就已经开始卷起来了。这其中,OpenAI 发布的 o1-preview 和深度求索发布的 DeepSeek-R1 是两个关键里程碑,Gemini 2.0 Flash Thinking 和 QwQ 穷追不舍,这些都被称为推理模型(或思考模型),他们引入了 推理时计算(test-time compute) 的概念,也就是在推理阶段投入更多的计算资源,例如评估多个潜在答案、进行更深入的规划、以及在给出最终答案前进行自我反思等。
心理学家卡尼曼提出,人类大脑中存在两套系统:系统1和系统2,系统1是无意识的、快速的、直观的,而系统2则是有意识的、缓慢的、需要付出心理努力的,这两套系统在我们日常生活中相互作用,共同影响着我们的思考、决策和行为。
传统模型和推理模型就好比是人类大脑中的系统1和系统2,推理模型用更长的等待时间,换取更高质量、更具实用性的结果。就像著名的 斯坦福棉花糖实验,那些为了获得两个棉花糖而坚持忍耐更长时间的孩子,往往能取得更好的长期成就。推理模型的发展其实是在引导用户接受一种 延迟满足 的观念,为了获得更好的结果,用户需要等待更长的处理时间,无论你是否喜欢这种用户体验,大多数用户都已经默默接受了这一点。
正是在这个背景下,Deep Research 开始流行起来,因为 Deep Research 天生需要深度思考和推理。
Deep Research 示例
Deep Research 和 Deep Search 的概念由于并没有明确定义,往往被混淆,但一般来看,Deep Research 相比于 Deep Search 有几个更明显的特征:
- 引入推理模型,思考时间更长,能处理更复杂的任务;
- 能使用更多的工具,比如操作电脑、访问浏览器、编写代码等;
- 更擅长论文写作和报告生成;
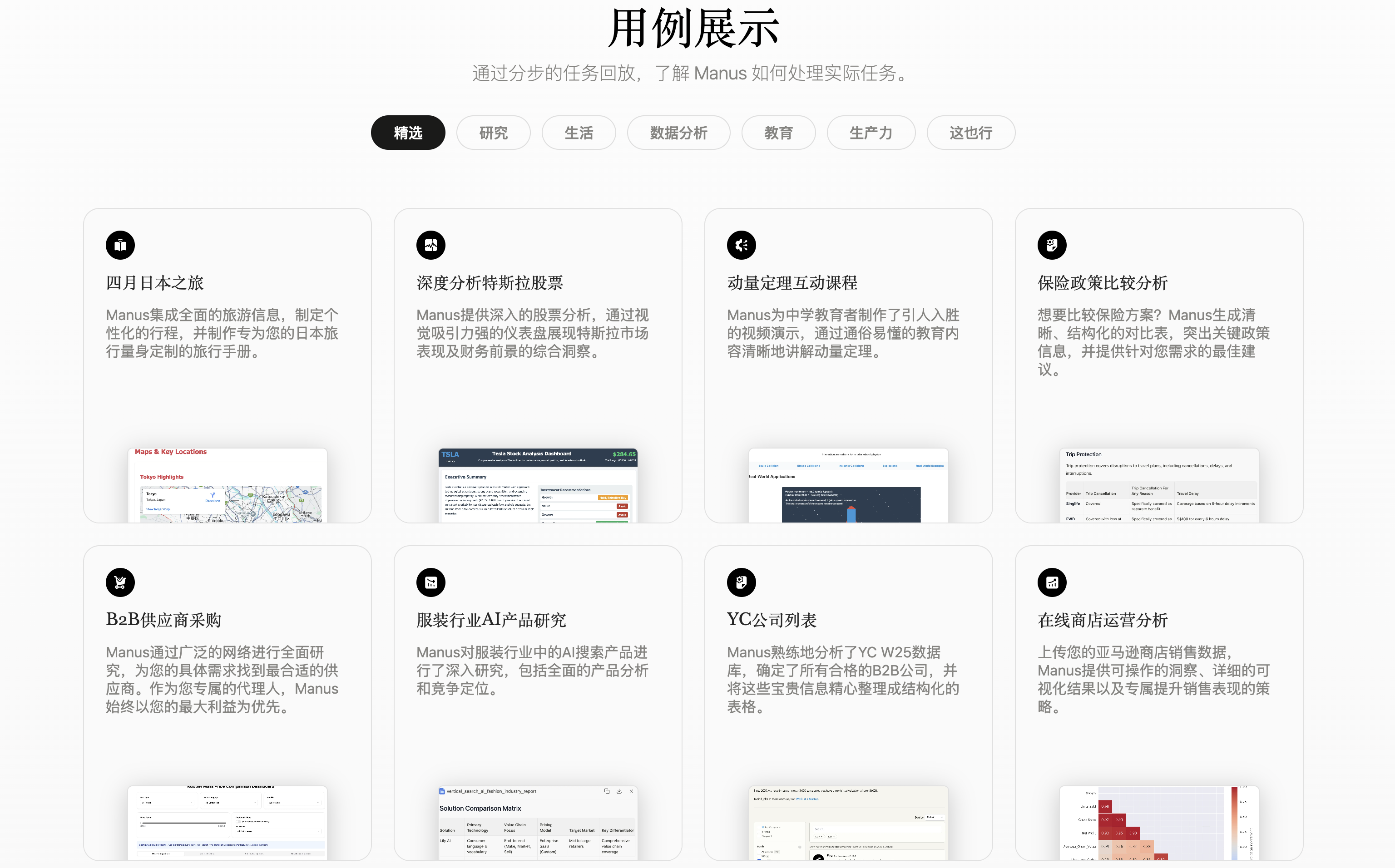
下图是 Manus 的部分用例展示:
下图是 AutoGLM 沉思 的部分用例展示:
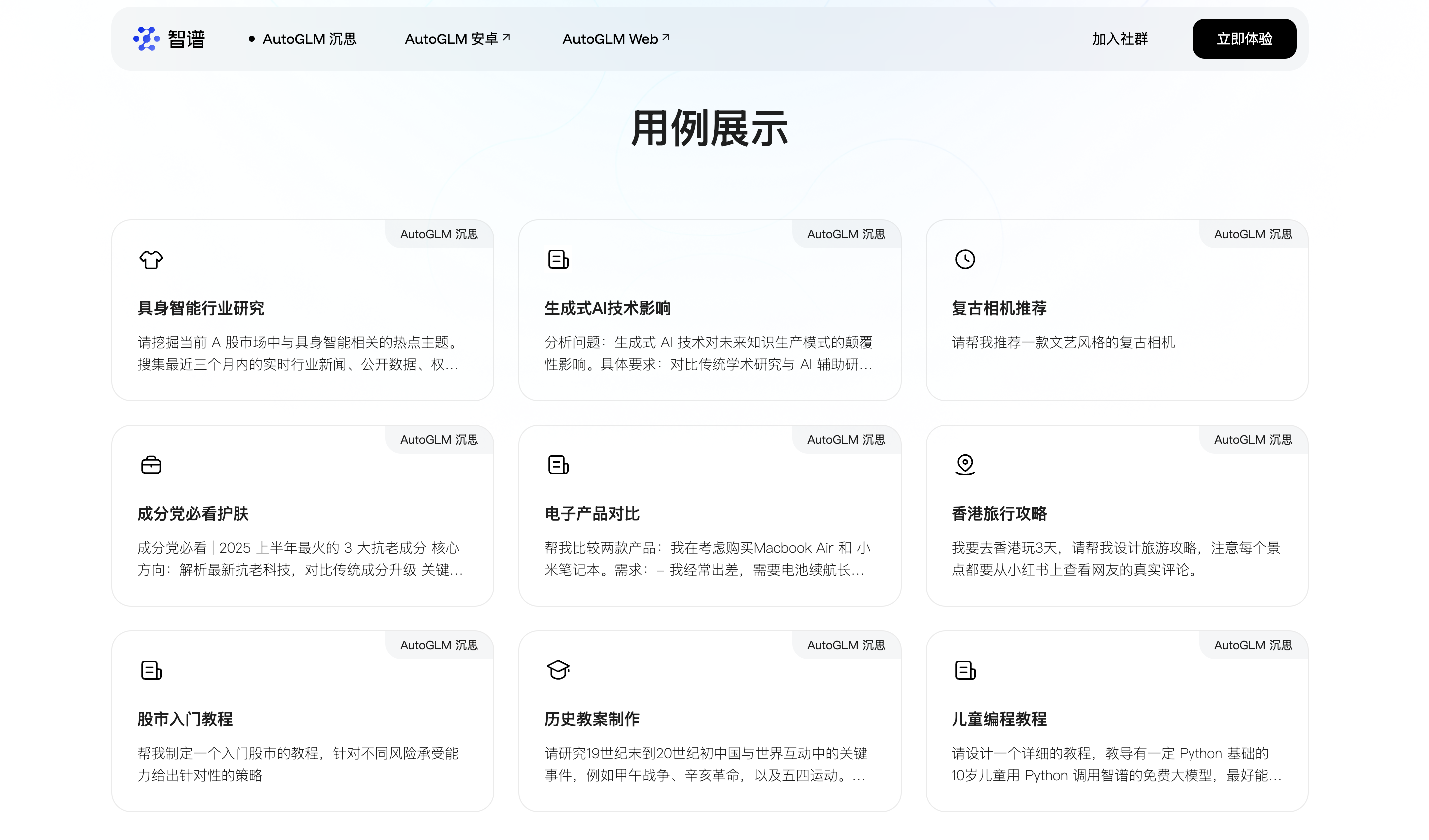
这两个用例展示里列出了一些 Deep Research 的典型场景:解决复杂任务、撰写行业研究报告、生成旅游攻略、竞品对比、教案制作等。比如 AutoGLM 沉思可以通过任务拆解和浏览器轻松解决 《哪吒2》中哪吒配音的老家天气怎么样? 这种多跳问题:

Gemini 的 Deep Research 功能可以结合思考模型和联网搜索对话题进行深度剖析:
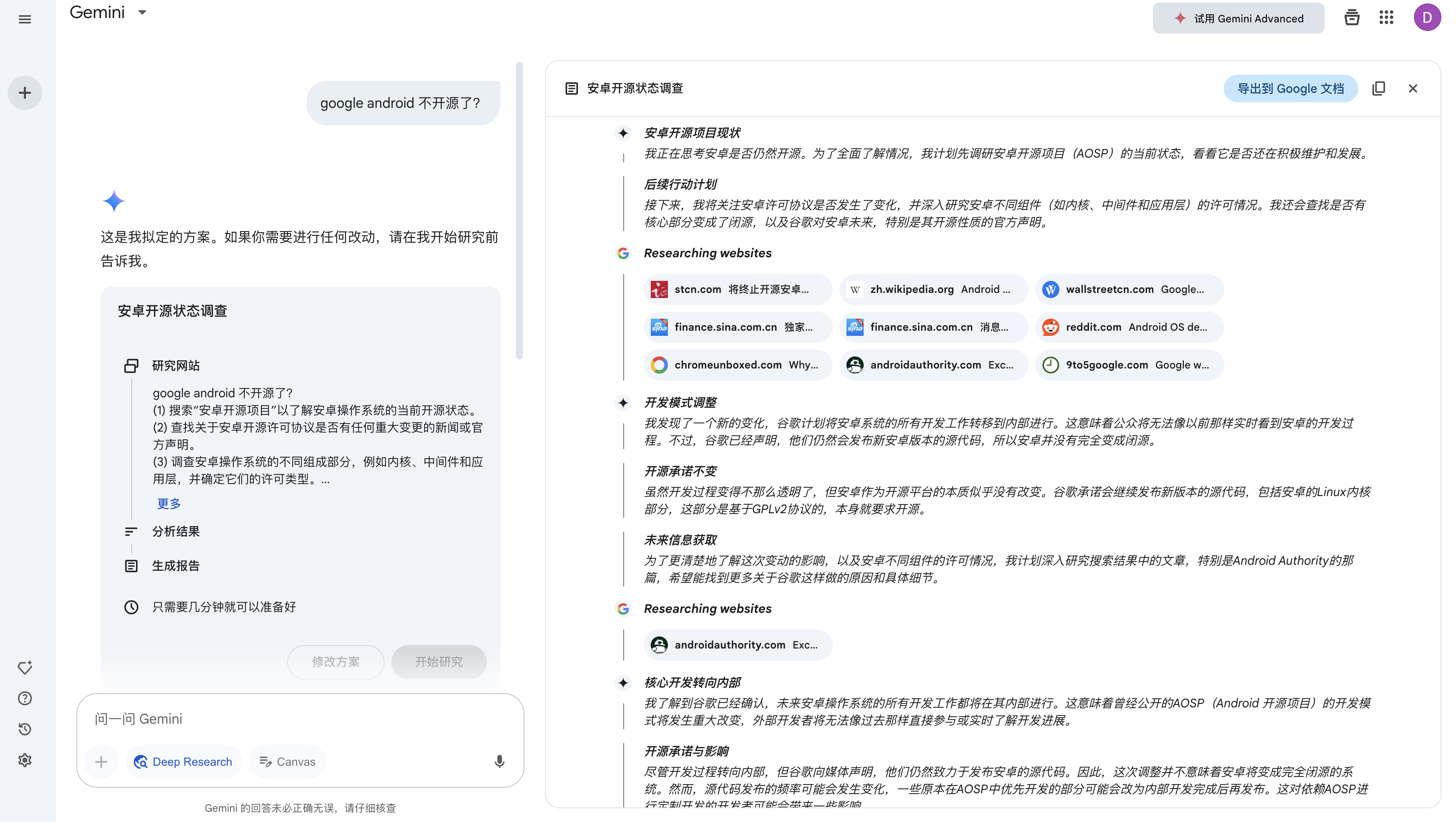
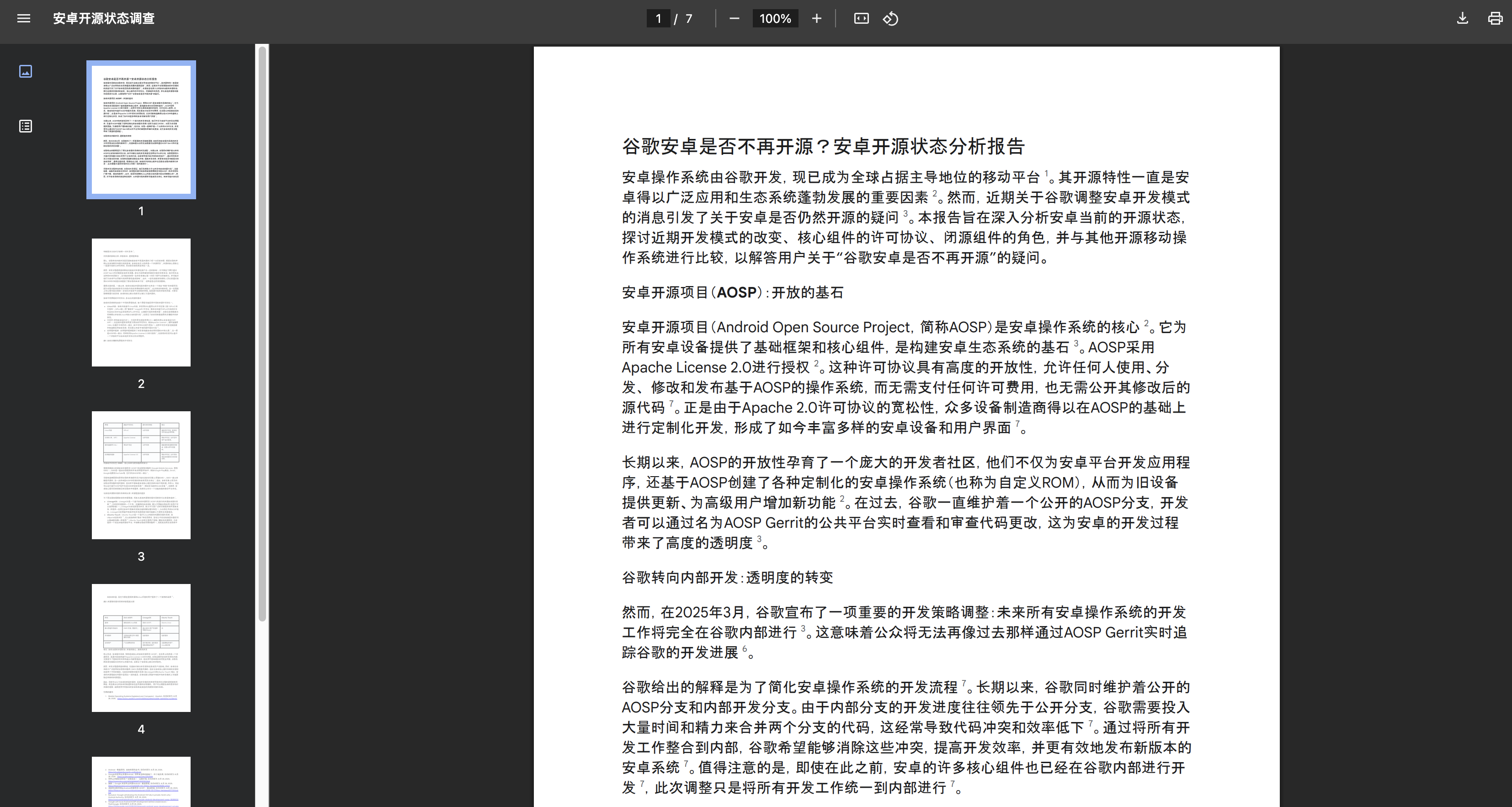
生成一份长达 7 页的 PDF 文件:
最近秘塔推出了一个 生成互动网页 的功能,可以将搜索的内容整合成一份图文并茂的研究报告:

Deep Research 开源实现
目前 Deep Research 开源实现非常多,这一节将挑选几个比较流行的逐一介绍下。
assafelovic/gpt-researcher
GPT Researcher 也被简称为 GPTR,应该是大模型兴起之后最早一批专注于研究报告生成的开源项目。受 Plan-and-Solve、RAG 和 STORM 等论文的启发,GPT Researcher 将系统划分成 规划者(Planner)、研究者(Researcher) 和 发布者(Publisher) 三个部分:
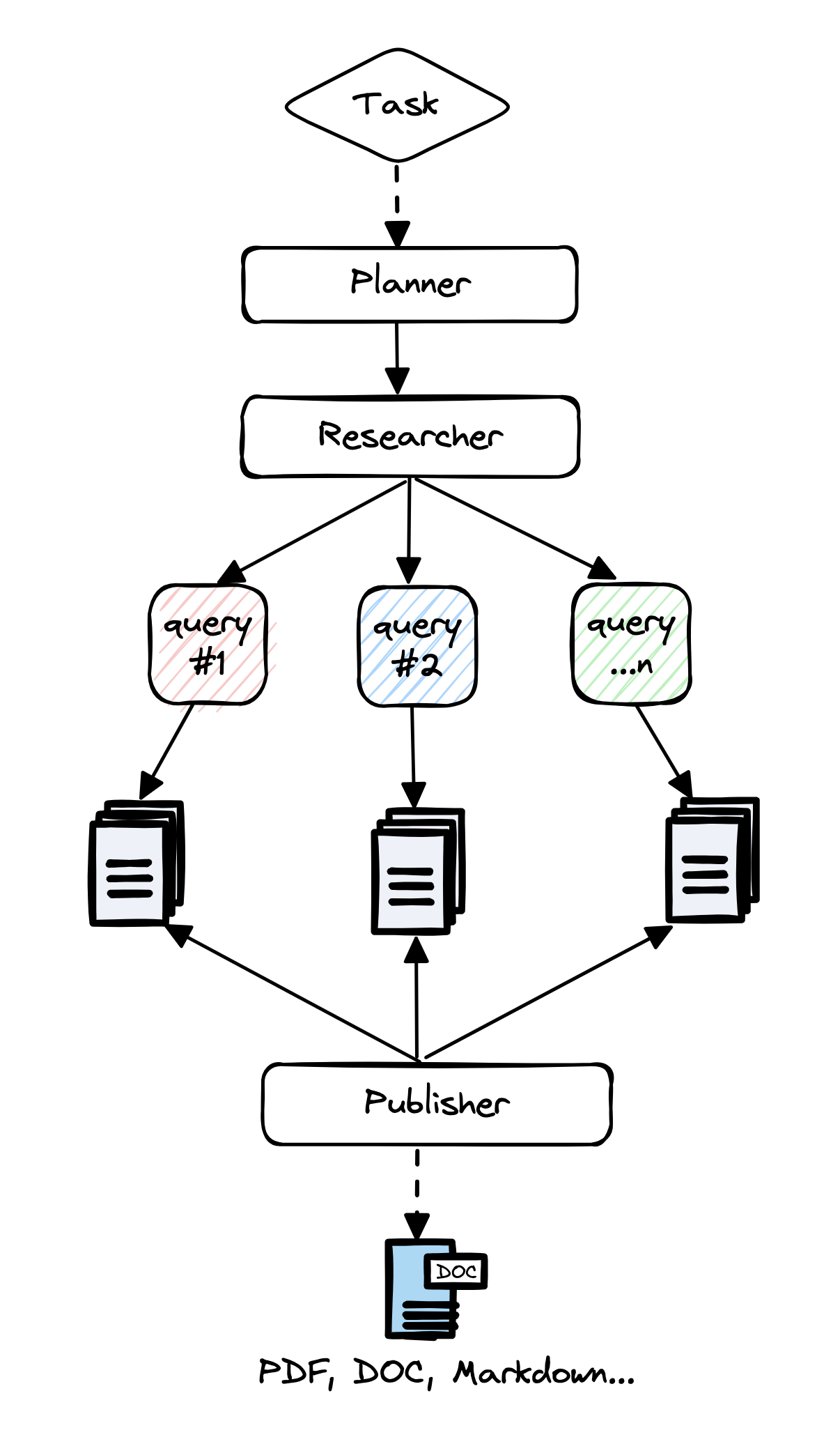
其中规划者生成研究问题,而研究者根据每个生成的研究问题寻找最相关的信息,最后,发布者筛选和汇总所有相关信息,并生成一份研究报告。
要体验 GPT Researcher,首先下载源码:
1 | |
然后进入项目根目录:
1 | |
目录下有一个 .env.example 文件,复制这个文件并重命名为 .env,然后填写 OPENAI_API_KEY 和 TAVILY_API_KEY 两个环境变量:
1 | |
接下来安装所需依赖:
1 | |
安装完成后运行:
1 | |
这时就可以通过 http://localhost:8000 访问并使用 GPT Researcher 了。
要注意的是,这个页面是用 纯 JS 实现的,不依赖其他 JS 库,所以体验不怎么好,而且更新有些滞后,有些最新特性体验不了。官方还提供了另一个 Next.js 版本 的实现,可以通过下面的步骤启动:
1 | |
启动成功后,可以通过 http://localhost:3000 访问新 UI:
新 UI 相对于老 UI 在左下角多了一个高级选项: