MySQL 优化之 Covering Index
在网上随便搜搜,就能找到大把的关于 MySQL 优化的文章,不过里面很多都不准确,说个常见的:
1 | |
一般来说,很多文章会告诫你类似这样的查询,不要在 “a” 字段上建立索引,而应该在 “b” 上建立索引。这样做确实不错,但是很多时候这并不是最佳结果。为什么这样说?这还得先从索引来说起。
索引
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
在 MySQL 中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文讨论的主要是 InnoDB 的 B+Tree 索引,它又可以分为两类:
- 聚簇索引
- 非聚簇索引
聚簇索引又称为聚集索引或主键索引,它并不是一种单独的索引类型,而是一种数据存储方式。在 InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶子节点称为 leaf page,其 data 域保存了完整的数据记录。也即我们所说的数据行即索引,索引即数据。
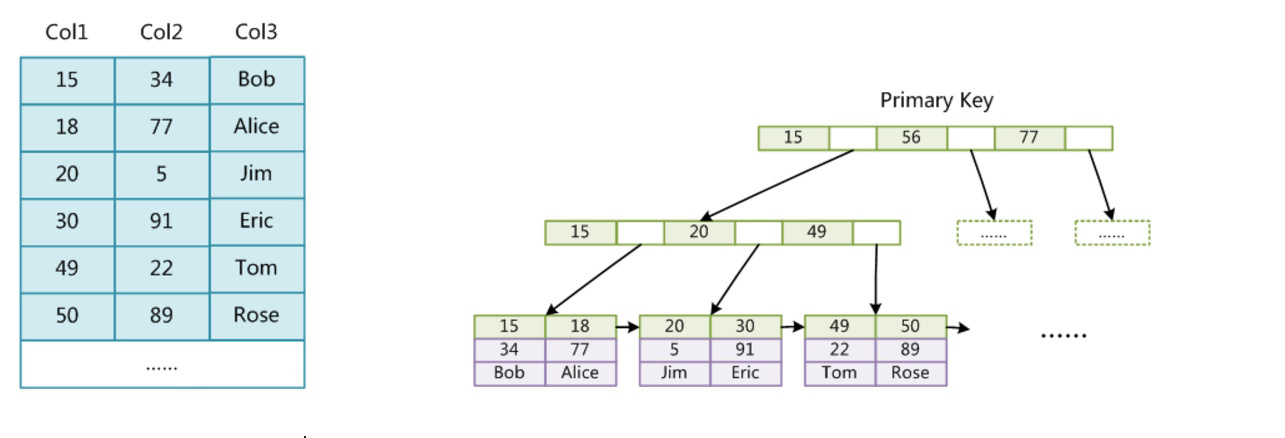
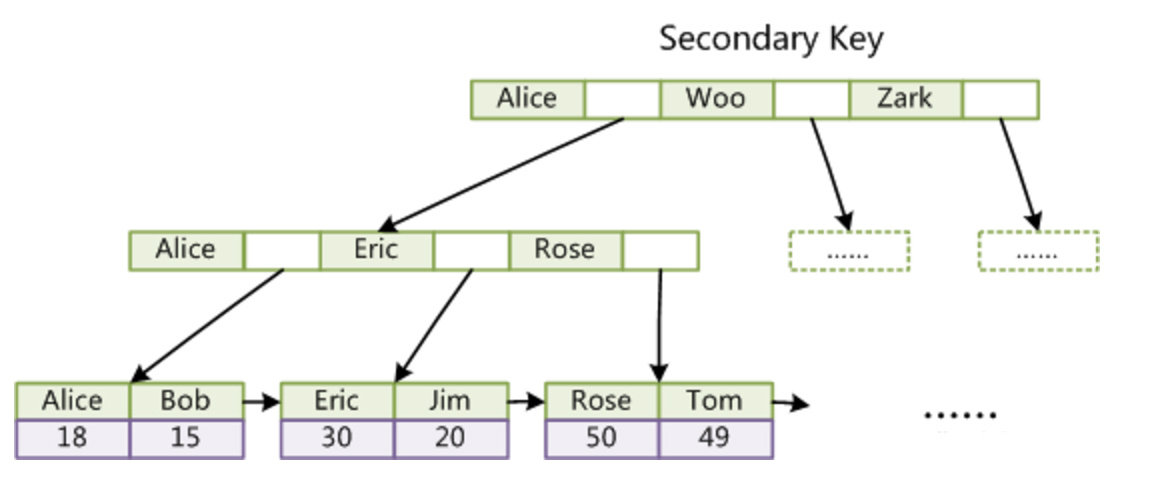
非聚簇索引是相对于聚簇索引来说的,我们又称为辅助索引或二级索引。 InnoDB 的二级索引 data 域存储的是相应记录主键的值而不是物理位置的指针。
回表
了解了 InnoDB 索引的实现方式,我们就很容易理解“回表”这个概念了。
聚簇索引这种实现方式使得按主键的搜索十分高效,但是二级索引搜索需要检索两遍索引:首先检索二级索引获得主键,然后用主键到主索引中检索获得记录。
让我们回到开头说的那个例子:
1 | |
我们先来分析一下查询的处理过程:在执行查询时,系统会查询 “b” 索引进行定位,然后回表查询需要的数据 “a”,也就是说,在这个过程中存在两次查询,一次是查询索引,另一次是查询表。
那有没有办法用一次查询搞定问题呢?有,就是 Covering Index!
说到这里你可能会想起来 MySQL5.6 中引入的 MRR(Multi-Range Read,多范围读),它是专门来优化二级索引的范围扫描并且需要回表的情况。它的原理是,将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机 IO,转变成顺序 IO。MRR 的优势是将多个随机 IO 转换成较少数量的顺序 IO,所以对于 SSD 来说价值还是有的,但是相比机械磁盘来说意义小一些。
Covering Index
所谓 Covering Index,就是说不必查询表文件,单靠查询索引文件即可完成。使用覆盖索引的好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的 IO 操作。
具体到上边的例子中就是建立一个复合索引 (b, a),当查询进行时,通过复合索引的 “b” 部分去定位,至于需要的数据 “a”,立刻就可以在索引里得到,从而省略了表查询的过程。
如果你想利用 Covering Index,那么就要注意 SELECT 方式,只 SELECT
必要的字段,千万别SELECT * FROM …,因为我们不太可能把所有的字段一起做索引,虽然可以那样做,但那样会让索引文件过大,结果反倒会弄巧成拙。
如何才能确认查询使用了 Covering Index 呢?很简单,使用 EXPLAIN
即可!只要在 Extra 里出现Using index就说明使用的是 Covering
Index。
这里再举两个栗子,让大家印象深点。
栗子一
在文章系统里统计总数的时候,一般的查询是这样的:
1 | |
当我们在category_id建立索引后,这个查询使用的就是
Covering Index。
栗子二
在文章系统里分页显示的时候,一般的查询是这样的:
1 | |
通常这样的查询会把索引建在created字段(其中id是主键),不过当LIMIT偏移很大时,查询效率仍然很低,这时这个查询最好改成下面的样子:
1 | |
此时,就可以在子查询里利用上 Covering Index,快速定位 id,查询效率嗷嗷的。
基于我的测试数据,这两条语句的查询耗时分别是“0.08 秒”和“0.01 秒以内”,8 倍的差距啊!不由又想起了地精的经典语录
时间就是金钱,我的朋友!
补充:InnoDB 引擎层是会对二级索引做自动扩展,优化器能识别出扩展的主键。详情可以参考这篇文章。
我们再来看看这两条语句分别对应的执行计划
1 | |
通过 EXPLAIN 我们可以很明显的看出,第一个查询没有用到索引,Extra 里是“Using filesort”,这是我们应该尽量避免的情况。而第二个的 Extra 是“Using index”,所以这两者间效率上的差距就显而易见了。
总结
Covering Index 并不是什么很难的概念,但是有些人还不了解它或忽视它的价值,希望本文能给你提个醒。
参考
MySQL 覆盖索引 MySQL 索引背后的数据结构及算法原理 MySQL 认识索引 谈谈 SQL 查询中回表对性能的影响 MySQL 优化之 MRR (Multi-Range Read:二级索引合并回表) 关于 MySQL InnoDB 表的二级索引是否加入主键列的问题解释